Mon Devoxx 2022 à moi !

ENFIN !! je crois que c’est le mot qui résume le plus l’attente (3 ans quand même !), les retrouvailles, les allers et venues dans les couloirs Neuilly et Paris, l’arrêt aux stands, les discussions avec les copains et les copines… Que ça fait du bien ! Retour en images et en texte de cette spéciale 10 ans de DevoxxFR…
Mardi 19 avril : prépa physique et mentale
Cela fait deux jours que le stress gagne chacun de mes organes vitaux et m’empêche de correctement dormir et manger. Il y a quelques jours j’apprends que je donnerai ma conférence “Rendez l’agilité aux développeurs et développeuses !” en amphi bleu. Le grand amphi bleu. L’ÉNORME amphi bleu. Il n’y a plus qu’à espérer que les spots m’aveuglent suffisamment pour que je n’y voie rien !
Après un faux départ (oubli de chargeur de portable, c’eut été dommage…), en route pour Paris depuis Saint Pierre des Corps (à 4km de Tours 😜).
On retrouve les potos pour partager un repas sympathique et on oublie la pression, car comme dirait un grand homme, qui vit avec moi : “La pression ça se boit !”
Mercredi 20 avril : tranquille !
Ce que l’on retrouve
Par rapport aux autres éditions, il y a beaucoup de choses qui n’ont pas changé et qu’on aime retrouver (d’ailleurs, on vient surtout pour ça !) : les gilets rouges qui assurent, les “oh tiens tu es là toi ? ça va ? la famille ? imotep !”,
Il y a aussi la partie stand que j’affectionne particulièrement : il y a trois ans, lors de l’édition 2019, je cherchais, l’âme en peine, une solution à mon avenir professionnel. CV à la main, j’avais fureté sur les stands et énormément échangé sur la vision des équipes de dev alors. C’est là que l’arrivée de 10 techs en sweat Apside m’avait tapée dans l’oeil. Une année chargée d’émotions donc, qui me fera toujours aimer échanger avec les boîtes présentes.
Ce qui change
Non mais vous avez vu ce stand d’accueil ?? Cette bannière magistrale, cette organisation impeccable, ces gilets rouges au top !
 C’est un bonheur de venir retirer son pass la veille !
C’est un bonheur de venir retirer son pass la veille !
Bien-sûr, n’ayant pas eu la chance de pouvoir participer à la session 9 3/4 , c’est ma première aventure Devoxx masquée. L’année prochaine je viens avec un loup ! (le masque, pas l’animal, ça ne serait pas très pratique…)
Les couloirs sont jonchés de photos souvenirs des années précédentes, depuis 2012 : je peux vous dire que personne n’a pris une ride !
La révolution (wasm) est incroyable parce que vraie - Philippe CHARRIERE et Laurent DOGUIN

Première université de 3h pour ce mercredi matin. Ce que j’apprécie avec ces deux grands messieurs, c’est que ce sont des gens intelligents qui ne vous font pas sentir bêtes (merci à eux !) : je comprends quand ils m’expliquent quelque-chose 😁
Ça parle Flash, ActiveX, applets Java, bref, ça ravive des souvenirs lointains. On arrive au Javascript mais en termes de design et de graphisme, c’est à parfaire => qu’est-ce qui peut nous sauver ? EMScripten avec asm.js ? joli essai. WebAssembly !! le fameux wasm : on va régler les soucis des navigateurs, sans remplacer Javascript pour autant, ne confondons pas ! Il s’utilise partout, y compris sur JVM.
Wasm s’exécute partout : Javascript (navigateur et Node.js) GraalVM, runtimes… et parle toutes les langues : C/C++, Rust, Golang, Swift… et se voit dédié certains langages : AssemblyScript et Grain par exemple. Je vous invite à regarder la slide 35 qui récapitule tout bien => j’indiquerai le lien vers la présentation ASAP.
Ensuite nous passons à la partie démo, vous la trouverez dans la vidéo YouTube sur la chaîne DevoxxFR : à venir. ça parle de pointeurs de mémoire (oups!), d’émojis 😉, d’accès au système d’exploit avec WASI (spoiler : jeu de mot pictural à suivre), wasmer, wasmtime, wasmedge…

On passe un très bon moment : merci à tous les deux !
Pour suivre Laurent et Philippe sur twitter, ça se passe par là : @ldoguin et @k33g_org
Lien vers les slides
Lien vers la vidéo de Philippe et Laurent

Architecturoplastie hexagonale d’un backend Node.js : Opération à coeur ouvert - Jordan NOURRY, Adrien JOLY et Julien TOPCU
Bienvenue à Shodopital, nos trois internes charcutent et décortiquent du code pour en tirer le plus de bénéfices possibles. Première biopsie clean-codienne : on clarifie notre code !

On précise nos paramètres, on refactore doucement mais sûrement, on reboote le patient (si ! si ! c’est possible !) et on redonne du sens pour éclaircir la compréhension du code. Même les tests d’intégration présents sont piégeux ! et les changements en codebase ne sont pas trackés => comment faire ?
Non, on n’utilise pas un bistouri, on va casser l’ordinateur… Non, on va plutôt s’intéresser au comportement attendu des APIs et créer des approval tests. Et on teste régulièrement ! à chaque modification ! le pas à pas. On supprime les undefined et les null.
Le nom des fonctions doit signifier ce que fait la fonction : on s’allège ainsi la charge mentale de relecture de tout le code pour le comprendre.
Enfin, on centralise le fonctionnel et sa complexité : on arrête de la disperser un peu partout dans notre architecture ! (à bon entendeur…)
Le but de l’architecture hexagonale, est donc d’inverser le sens de la dépendance entre la couche domain et la couche de persistence, normalement rencontré dans le modèle classique.
Controller ->use-> Domain <-use<- Persistence
Domain devient un hexagone où les objets métiers sont centralisés.
Pour suivre Jordan, Adrien et Julien, ça se passe par là : @JkNourry , @adrienjoly et @JulienTopcu
Lien vers les slides
Lien vers la vidéo de Jordan, Adrien et Julien

Et n’oubliez pas, nous co-organisons, avec CraftsRecords et TADx, le Tremplin des speakers le 3 mai à Tours pour donner la chance à des speakers débutants de gagner une conférence au Camping des speakers, dans le Golfe du Morbihan les 9 & 10 juin 2022. Inscriptions pour faire partie du public-jury du tremplin le 3 mai => lien eventbrite
Rendez l’agilité aux développeurs et développeuses ! - votre humble serviteuse
Le palpitant accélère petit à petit depuis la fin de la dernière université (peut-être même pendant). Trop pour me concentrer sur une autre conférence. 248 inscrits sur l’application Devoxx, syndrome de l’imposteur au max, je pense à mon premier jury de guitare classique quand j’étais au CP : même envie irrésistible de monter sur scène mais pour faire une blague et repartir aussitôt.
J’attends sagement mon tour, entourée des personnes adorables (Stéphane en premier mais aussi Jérémy, Faustine, Corentin, Yann-Thomas, Olivier, Christophe, Thibault, et j’en oublie ! pardon…). Je passe dans les mains du technicien (adorable aussi), Adrien et Arnaud me rassurent à la dernière minute : merci à tous !

J’ai adoré la prise de risque, j’ai aimé préparer, répéter, partager, rencontrer des gens grâce à ce partage… Un grand merci aux organisateurs et aux membres du comité de sélection de m’avoir offert cette occasion unique !
Pour me suivre, ça se passe par là : @klf37
Lien vers les slides
Lien vers la vidéo
Créer & distribuer un plugin pour Kubernetes en quelques minutes ? Easy ! - Aurélie VACHE et Gaëlle ACAS
Grâce à une super organisation des talks, j’ai pu assister à cette présentation pêchue et accessible pour nous autres communs des mortels !

Des gophers et une partie théorique plus tard (ou on se rend compte que l’important dans kubectl, ce n’est pas de savoir le prononcer, mais bien de l’utiliser !), place à la pratique : live-coding !! La présentation est fun et accessible : on apprend autant qu’on passe un bon moment. Le bon conseil : ne pas hésitez à partager ses trouvailles par des index Krew personnels à défaut de pouvoir l’ajouter dans le Krew index : tout est utile !

Et pour les commandes ou plugins utiles et les bonnes pratiques : revisionnez à souhait la présentation (vidéo bientôt disponible en lien ici) ou référez-vous aux sketchnotes d’Aurélie sur le sujet (lien ici bientôt).
J’ai beau avoir déjà vu la présentation à la TADx de février 2021 à distance et au JugSummerCamp de septembre 2021, je ne me lasse pas : Gaëlle et Aurélie sont à voir et à connaître absolument !
Pour suivre Aurélie et Gaëlle, ça se passe par là : @aurelievache et @Gaelleacas
Lien vers les slides
Lien vers la vidéo d’Aurélie et Gaëlle
Be jealous : j’ai un sticker collector !!

Bilan de la première journée
Ouf ! sacrée journée ! je vais laisser la pression redescendre, participer au dîner des speakers, rencontrer encore plein de gens formidables, merci à toutes et tous !

On vous donne rendez-vous demain jeudi 21/04 à 20h pour le BOF TADx - Tours Agile & DevOps experience à 20h autour de fabuleux DevRel ! (TADx, injustement non renommé PADx pour Paris Agile & DevOps experience pour l’occasion, mais j’aurai le dernier mot un jour…)
Jeudi 21 avril : on recharge les piles !
DevoxxFR va enfin pouvoir commencer : mon estomac est dénoué ;-) Beaucoup plus de monde à l’entrée, l’amphi Bleu se remplit en quelques minutes seulement.
Première Keynote : les 10 ans de DevoxxFR !!!
Revival ! montée sur scène façon concert de rock : éclairage, fumée, et… rockstars !! Nicolas, Antonio et Zouheir nous partagent les coulisses de DevoxxFR, depuis sa germination, sa naissance, son annonce et son expansion !

L’équipe entière monte sur scène et entonne un joyeux anniversaire des 10 ans des plus envolés : un grand merci pour tout ce que vous faites, vos partages, vos galères, votre fatigue mais toujours vos DevoxxFR pleins de succès ! Fière de vous avoir croisés et de faire un peu partie de l’aventure en tant qu’attendee depuis les 5 dernières sessions.

A revoir absolument : les photos collectors !!!
Encore un grand merci !
Lien vers la vidéo
10 ans de tech à travers le podcast Niptech - Benoît CURDY, Michael MONNEY et Baptiste FREYDT
Il existe des groupes qui fonctionnent parce qu’ils ont tout compris : partager dans la bonne humeur. C’est exactement le cas de Niptech ! Au travers de leur rétrospective, de leur réussite, des aléas de la vie, des tentatives d’innovations, des retours aux valeurs sûres : on partage avec bonheur nos propres tentatives de maintien de communauté, pour toujours plus lui apporter et la garder précieusement. Car oui : c’est un vrai plaisir de partager !
Merci à tous les trois !
Lien vers la vidéo de Benoît, Michael et Baptiste

Slow tech : il est urgent de changer le système - Frédéric BORDAGE
Présentation très claire et très concrète des solutions que l’on peut toutes et tous mettre en place au quotidien pour hacker le système et faire avancer la problématique de notre impact écologique.
On découvre la notion d’obégiciel : la croissance exponentielle du poids de nos utilisations logicielles. Il n’y a pas que la partie extraction de minerais ou de fabrication qui puise dans les réserves de notre belle planète encore bleue, mais pas pour longtemps. On évoque l’éco-conception, mais surtout de la Slowtech.
Slow.tech (low + high).tech
Le numérique étant une ressource non renouvelable car à notre rythme de consommation de matières premières, on ne pourra plus fabriquer d’ordinateur (le truc que je suis en train d’utiliser pour écrire ce blog…). Accepter de rendre son service moins high-tech, c’est aussi accepter de le rendre plus accessible potentiellement : rendre plus simple l’accès aux informations.
Conclusion : concentrons-nous sur ce que la tech sert vraiment, et pour tout le reste, gardons notre bon sens !
Pour participer activement et aider, ça se passe ici : collectif@greenit.fr
Lien vers la vidéo de Frédéric
Comprendre les enjeux de consommation de ressource et d’énergie dans le secteur numérique - Quentin ADAM et Pierre BEYSSAC
On debunk sur les impacts écologiques de l’IT ! Pour cela, on découpe trois domaine :
- la fabrication, liée à l’extraction concrète des matières premières et de la nécessité de l’énergie
- le run, actuellement rapproché au réseau et au rapport Watt/Go
- la fin de vie, de plus en plus liée à la récupération

Concernant le run : le pilotage de la consommation mais aussi de la production, intégrer la notion de l’heure et de la localisation à la stratégie de calcul, permettraient de corriger la marge d’erreur des calculs unitaires et communiqués actuels.
On compare la consommation des différents , mais aussi les pays, les secteurs économiques : on apprend plein de choses concrètes.
La morale est de prendre du recul sur les réels impacts : éteindre un composant électrique, ça peut être une bonne pratique, mais s’il y a risque de l’abîmer voire de le détruire (par baisse de température, par sur-intensité au redémarrage…) quitte à racheter ce composant et donc de le fabriquer… et donc de ré-extraire des matières premières… réfléchissons et ne prenons pas tous les chiffres qui nous sont communiqués sur les réseaux ou via les médias comme argent comptant.
La métrique idéale qui nous permettrait de facilement nous positionner est beaucoup plus complexe que le simple Watt par Gigaoctet.
Concernant la fabrication, il ne faut pas ignorer le risque d’amoindrissement des matières premières. L’idée là est de se dire que pour chaque problématique de multiples solutions de contournement existe. Et que l’impact écologique étant un problème, il faut se pencher sur les solutions de contournement.
L’idée est de pérenniser nos utilisations : investir sur des objets qui tiennent dans le temps plutôt que de multiplier les achats d’objets de piètre qualité. Cela me rappelle une discussion super intéressante avec un collègue, un jour où je me posais la question de revendre ma voiture essence encore en bon état pour une voiture neuve électrique, je me suis vue répondre : “la meilleure voiture est celle que tu n’achètes pas. Pousse ta voiture tant qu’elle fonctionne, et repose toi la question plus tard : peut-être alors qu’encore d’autres solutions apparaîtront entre temps”.
Retenir : une mesure sans marge d’erreur, n’est pas une mesure.
Vous voulez en savoir plus ? bien-sûr je vous invite à aller voir la vidéo de retransmission mais aussi les émissions de Monsieur Bidouille (lien à venir).
Pour suivre Quentin et Pierre, ça se passe par là : @waxzce et @pbeyssac
Lien vers les slides - à venir
Lien vers la vidéo de Quentin et Pierre
Licences open source : entre guerre de clochers et radicalité - Pierre-Yves Lapersonne
Quelle est la meilleure ou la pire licence opensource ? Pas facile.

Il y a différentes notions à prendre en comte : le droit d’auteur, le copyright, la non discrimination, les brevets… Il existe MIT, BSD sur plusieurs versions, avec plus ou moins de conditions (citations, références…).
Comme c’est compliqué, notamment pour les brevets, il vaut mieux se référer à un juriste. Là existe Apache 2.0.
Pour des licences LPL ou LGPL, il existe la notion de licence LIBRE, COPYLEFT, COPYLEFT faible, MOZILLA PUBLIC LICENSE 2.0, LGPL V3
Pour la licence GPL V3, il y a COPYLEFT FORT, GPL V3, AGPL V3
Bon à savoir : AppStore et iTunes d’Apple ne sont pas adaptées aux licences GPL, contrairement avec Google Play
Et puis, il y a les licences éthiques aujourd’hui, par l’Organisation for ethical source, imposant le non-nucléaire, le non-militaire, la non destruction de l’environnement, la non-violence de manière générale.
Pour faire bref : c’est compliqué ! et souvent les choix semblent radicaux et provoquent des réels cas de conscience. Et c’est bien : cela fait se poser les bonnes questions et reflète les problématiques ambiantes qu’on n’aime pas trop mettre à jour. Peu de procès et de jurisprudence pour le moment, du fait de la récence des licences, donc les ressources juridiques sont encore peu étoffées.
Je rajoute ma propre morale : on a tous un rôle à jouer dans l’éthique des entreprises, y compris quand on est développeuse ou développeur. Et là je vous conseille de re-visionner une des keynotes qui m’avait marqué à DevoxxFR en 2017 : De la responsabilité des ingénieurs d’Eric Sadin, à voir ici
Pour suivre Pierre-Yves, ça se passe par là : @pylapp
Lien vers les slides
Lien vers la vidéo de Pierre-Yves
Simplifiez vos revues de code avec le rebase interactif - Sonia SEDDIKI
Une première pour Sonia, et en salle Maillot s’il vous plaît !

On parle amélioration de revue de code : pouvant être vue comme laborieuse, elle intervient souvent en fin de longue période de développement dans un temps limité et donc avec peu de marge de manoeuvre pour corriger au besoin. A cela s’ajoutent les différents niveaux de revue à vérifier pour augmenter la qualité et la clarté de merge request.
Condition : avoir une MR avec des commits clairs et cohérents. Intervient alors le rebase interactif !
Commit du vendredi, TDD en faisant les tests en aval : on partage forcément des souffrances de tous les jours…
Grâce au “git rebase -i feature”, on peut lister l’ensemble des étapes / commit, les modifier, les éditer, les différencier, les découper … Les logs sont ainsi plus claires et parlantes. On peut ré-organiser l’historique des commits.
Pour re-rassembler des commits, pour encore plus de clarté, là encore une possibilité : fixup. On fusionne.
Et Squash ? Utilisé à la place de Fixup, il permet de conserver les messages en plus.
Attention : à faire sur vos propres branches ! pas des branches partagées ou dépendantes (encore moins sur main !!) dans le but de contrôler le périmètre géré. Si vous vous trompez : pas d’affolements ! on peut annuler avec un abort d’urgence qui revient au dernier état valide. Et les empilements de “git push” concurrents sont empêchés, ouf !
Très belle découverte : merci Sonia, et bravo !

Pour suivre Sonia, ça se passe par là : @sonia_seddiki
Lien vers les slides - à venir
Lien vers la vidéo de Sonia
Dois-je migrer en Reactive et comment ? - Christophe JOLLIVET
Apside represent ! C’est dans un amphi bleu bondé que la conférence de Christophe commence.

On parle d’abord de requête en mode impératif pour bien comprendre l’apport du réactif : lorsqu’on envoie une requête à un serveur, le thread arrive, la requête met un certain temps à s’exécuter puis le thread est retourné avec la réponse. Ce temps peut être conséquent, notamment quand on multiplie le nombre de threads. Ce qui est alors avantageux avec réactif est que le thread lancé permet d’exécuter la requête, mais il est retourné dans le pool immédiatement, le libérant.
Passer en réactif pour aller plus vite est donc une erreur mais ça va vous permettre de scaler très vite.
Dans un flux réactif, on trouve un publisher et un subscriber. Et pas de pressure, il y a backpressure ! pour ne pas sur-solliciter le subscriber, on régule le rythme : plusieurs façons de faire, mais il s’agit d’une bonne pratique obligatoire si vous ne voulez pas tout casser !
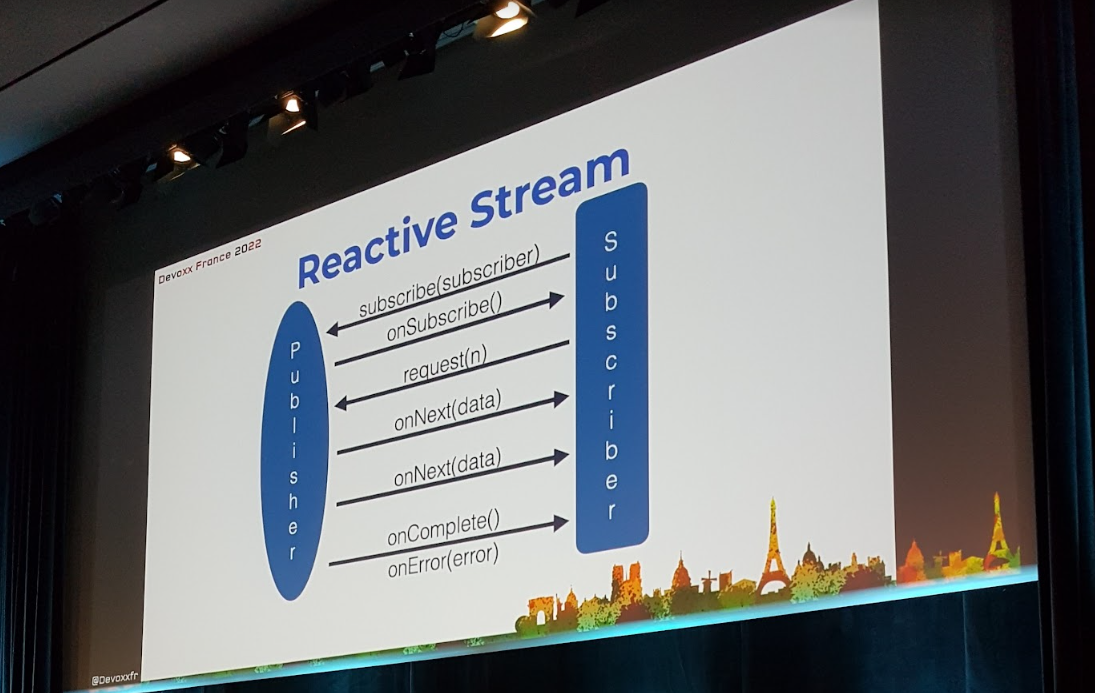
En termes de librairies, on est larges. Pour la présentation, c’est Spring qui est utilisé. En nous aidant des marble diagrams, on s’y retrouve un peu mieux que l’énorme javadoc disponible.
La syntaxe peut nous perdre : on ne sait pas toujours la répartition des threads, on tâtonne, mais c’est normal ! c’est comme tout : lancez-vous, testez et le métier viendra ;-)
On aborde ensuite WebMVC et WebFlux. On est vigilants aux imports, aux flux, aux monos : même si le code semble sensiblement identique de l’impératif, il y a ces modifications précieuses à apporter. On utiliser R2DBC en lieu et place de JDBC bloquant.
Mais attention : pas de pagination et, plus logique, pas de jointure autorisées : eh oui ! car qui dit jointure, dit blocage d’appel de requête ! On s’en sort cependant avec AfterConvertCallback, qui associe la jointure systématiquement, donc c’est tout ou rien. Pas de fetch non plus en automatique : c’est à coder par nous-même côté Hibernate.
Autres petits oups : on doit veiller à travailler avec des flux non bloquants, et il y en a ! Dès lors qu’on va vouloir loguer par exemple, il va falloir être vigilant. Pour cela, il existe BlockHound qui nous permet de déterminer si un appel bloquant est détectée dans le code. Ça nous évite de lire avec nos petits yeux tout myopes les nombreuses lignes de code à vérifier !
Quand on est prêt à déployer en production, on peut continuer d’utiliser Actuator qui permet de récupérer les informations utiles et nécessaires pour satisfaire les bonnes pratique DevOps.
Alors, on migre ou pas là ? Un grand oui si vous visez la scalabilité plus que la rapidité. La syntaxe est particulière et nécessite un peu d’apprentissage et d’habitude. En termes de persistance, on est limités mais les solutions telles que le NoSQL existent. Par contre c’est DevOps friendly.

J’ai adoré la présentation step by step en comparaison avec ce que l’on connaît de l’impératif : cela permet d’appréhender facilement et rapidement les concepts du réactif.
Pour suivre Christophe, ça se passe par là : @jollivetc
Lien vers les slides - à venir
Lien vers la vidéo de Christophe
Etre développeur : grandir et se développer - Gaëtan ELEOUET
“Etre développeur, ce n’est pas savoir coder. Savoir coder, ce n’est pas être développeur.”

Le rôle du développeur ou de la développeuse n’est pas seulement de répondre à un besoin par du code, mais assurer un service pérenne et de manière qualitative. Il faut pour cela s’astreindre à aller au-delà du simple code : creuser la qualité, améliorer la communication des équipes. C’est ainsi que Jeff Kent, un des signataires du manifeste agile, propose 9 règles de callisthénie.
On parle agilité, craftmanship : des manifestes qui mettent en exergue des pratiques déjà existantes, notamment la boucle de feedback la plus rapide possible et qui permette de toujours plus améliorer les pratiques de chacun. Ont été évoqués les principes SOLID, les propriétés CUPID.
Pour grandir, les 25 millions de développeurs dans le monde, il faut se préoccuper de la communication.
La notion même d’expérience, de séniorité est de plus en plus complexe : le nombre de technos explose et il est de plus en plus difficile de maîtriser toute une stack technique. Alors on est déjà bien content lorsque nous comprenons la stack. On n’est pas forcément un développeur ou une développeuse senior après 6 ans d’expérience : on n’a pas forcément pu tout voir ou voir suffisamment de choses pour nous considérer comme senior.
Éviter les pièges du super-héros, essayer d’agrandir sa zone de confort, expliquer le pourquoi on fait les choses, créer une culture véritablement bienveillante : autant de choses qui nous permettrons d’oser nous surpasser ou de tenter des nouveautés.
Je n’ai pas toujours réussi à comprendre le lien entre toutes les parties, j’ai dû louper des étapes (fatigue ?), aussi mes notes sont un peu un cumul d’idées éparses.
Pour suivre Gaëtan, ça se passe par là : @egaetan
Lien vers les slides
Lien vers la vidéo de Gaëtan
Comment j’ai aidé ma fille à lire avec le machine learning - Vincent OGLOBLINSKY
Retour d’expérience : lors de l’apprentissage de la lecture, les enfants décortiquent les syllabes une à une. Un des outils magiques qui existent est le digital. Le doigt quoi ! pointer son texte pour focuser son attention est une aide précieuse pour le déchiffrage.
Challenge : imaginer une solution qui aide à la lecture en déchiffrant une voix d’enfant alimentant une application web faisant marcher un speech-to-text like. Rencontrer des orthophonistes a permis de comprendre les phases de l’apprentissage de la lecture afin de coller au mieux à l’habileté mentale du cerveau qui apprend.

Le français, c’est pas facile : 26 lettres de l’alphabet, 36 phonèmes, 190 graphèmes associés… les combinaisons sont ultra-nombreuses !
Et le machine learning dans tout ça ? Il faut trouver des modèles de données en entrée de base, comprendre le fonctionnement du speech-to-text (donner du son court en entrée, puis traiter le signal pour ensuite dissocier la partie lexicale et le langage). Mais la complexité de l’affaire est de s’adapter à la tessiture des voix d’enfants, pour lesquelles les datasets d’entrée sont beaucoup plus rares.
Deux possibilités de modèles :
- un modèle déjà entraîné, moins maîtrisé mais existant
- un modèle à construire à partir de rien et donc avec besoin de beaucoup plus de données initiales pour pouvoir l’entraîner
C’est la première qui a été choisie, depuis tensorflow. Ajoutez du Python en local et déployez en JavaScript et ainsi le modèle pourra être utilisé dans le navigateur. Pour la collecte, l’interface propose d’enregistrer le son, le vérifier (donc le ré-écouter) et d’envoyer le fichier natif pour les nettoyer, les raccourcir…
Ensuite, on entraîne le modèle, et … on l’utilise ! on écoute en continu, on récupère la fréquence, on compare et on valide, ou pas !
A l’utilisation, l’enfant lit et sait visuellement si le déchiffrage est ok ou non. L’utilisation est ludique et laisse des perspectives d’ouverture multiples.
Intéressé(e)s ? essayez vous même avec teachablemachine
Pour suivre Vincent, ça se passe par là : @vogloblinsky
Lien vers les slides
Lien vers la vidéo de Vincent
Accéder à mon cerveau par une API - Sébastien BLANC
ÉNORME ! une entrée en matière sonore, visuelle et tellement tordante !

On va parler interface homme machine : que ce soit avec un clavier, un stylo optique mais aussi la souris, la Wiimote, le gyromètre sur les iPhone…
Si on va plus loin, on peut parler de Interface cerveau-machine.

“Il faut d’abord comprendre comment marche un cerveau, sachant que je suis un développeur J2EE.”
Les zones du cerveau sont spécialisées et permette de déterminer ce qu’il pense. Voici le streaming de cerveau de Sébastien :
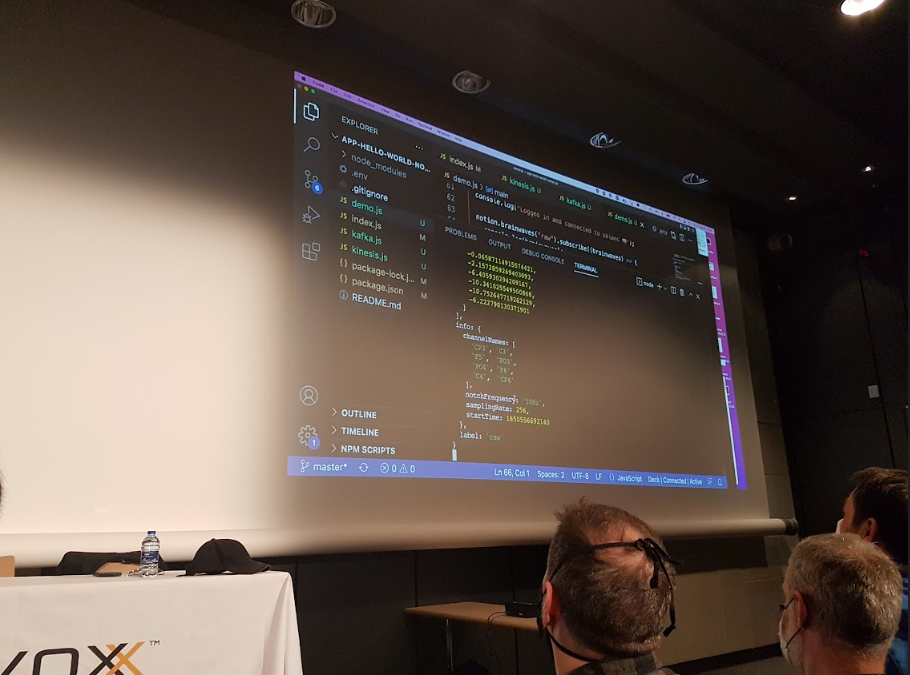
Et c’est plutôt très clair : cela indique qu’il est génial et que sa présentation fait mouche.
Plusieurs types d’ondes existent :
- Delta : c’est quand on dort
- thêta : lorsqu’on est en mode méditation
- alpha : quand on est en mode relaxation
- bêta : quand on est focus
- gamma : on le saura un jour plus précisément qu’aujourd’hui peut-être
On utilise Docker / Kafka pour… voir les données du cerveau de Sébastien sur un topic Kafka, et ça… ça n’a pas de prix ! On teste le calm, le focus mais surtout on commence à réellement utiliser les cas d’application : en fonction de ces taux de calm ou de focus, on va pouvoir lancer des commandes particulières. Il n’en faut pas plus pour laisser libre court à l’imagination de Sébastien pour la suite.
Il va construire un modèle et l’entraîner : mode deep learning ON via neurosity. Et on va parler Kinesis pour interagir avec son cerveau.
Nouvel exemple : via Brainflow, qui peut se connecter aussi au casque. Et enfin… tir de boulets de canon… par la pensée !!
BRAVO !
Pour suivre Sébastien, ça se passe par là : @sebi2706
Lien vers les slides
Lien vers la vidéo de Sébastien
Jouer à Minecraft avec une IA générée par GPT-3 - Wassim CHEGHAM et Tiffany SOUTERRE
Quand on discute sur Underscore on peut parfois se retrouver à se lancer dans des aventures impressionnantes mais tellement challengeantes ! Le POC présenté consiste à pouvoir donner des instructions au bot sous Minecraft via une intelligence artificielle (IA ou AI pour les english).
Après un rappel de ce qu’est le génialissime jeu Minecraft, les NPC (non-player characters), on voit comment interagir avec ces derniers grâce à OpenAI, GPT-3 qui, après un entraînement de folie, a donné Codex. Github Copilot lui, est capable de proposer des blocs de codes en fonction de ce qu’on souhaite faire faire à la fonction. J’aimerai clairement que ça existe pour les compte-rendus de réunions de 3h…
Bref, le joueur va donner une instruction, envoyée à Codex associée à un contexte.
On fait le tour du code, puis on passe à la partie démo, car nos deux speakers sont joueurs !
Vous êtes intéressé(e)s ? le code github sera open-sourcé ce soir 😇
Pour suivre Wassim et Tiffany, ça se passe par là : @manekinekko et @TiffanySouterre
Lien vers les slides
Lien vers la vidéo de Wassim et Tiffany
BOF TADx - Mais au fait DevRel c’est vraiment qu’un lanceur de paillettes ?
Très bon moment passé à se poser la question : qu’est-ce qu’un DevRel ? un Developer advocate ? un Technical Account Manager ? Plusieurs réponses différentes prouvent la richesse et la pluralité de ce qu’on met derrière ce rôle mais un point commun : le partage. Servir la communauté, être “un membre actif positif” - Horacio Gonzales
Merci à toutes et tous !



BOF Duchess France
Très bon moment là encore, passé à échanger sur la multiplicité des profils, des parcours, des valeurs… On parle syndrome de l’imposteur (qui à mon sens ne doit pas totalement disparaître pour permettre de rester humble dans son partage), études, partage de connaissances auprès des étudiants et étudiantes, encouragements, mentoring, entraide, mixité… Merci !! Ce fut très précieux pour moi pour la fin de cette deuxième journée intense !

Vendredi 22 Avril : ne te découvre pas d’un fil !
Bon, il faut se l’avouer, le vendredi matin est sans doute la journée la plus compliquée… la fatigue est réelle et il faut une vraie motivation pour arriver avant 9h au Palais des Congrès. Pour cela j’ai un respect incroyable pour les gilets rouges !
Je zappe donc volontairement les premières keynotes et en profite pour discuter par-ci par-là (on est aussi là pour réseauter) et prendre quelques goodies !
10 ans de Devoxx FR et de Java - Jean-Michel DOUDOUX
Il y a des gens qu’on rêve de voir un jour en conférence, en vrai. Jean-Michel DOUDOUX en fait partie. Et je ne suis pas déçue : un incroyable condensé de savoir dilué avec gentillesse et humour pendant 45 minutes.

Je salue particulièrement le difficile exercice de choisir les choix cornéliens de sujets à aborder sur les dix dernières années de la vie de Java.
J’ai retenu surtout :
- Java 8 et les lambdas, l’API Date & Time
- Java 9 en 2017 avec le try with resources et JShell, et les modules… qui ne font pas l’unanimité ! mais qui d’après Jean-Michel, devrait être une cible, pour des raisons de maintenabilité, performance mais aussi sécurité !
- Java 10 et l’instruction var
- Java 11 en 2018 avec l’API HTTP Client supportant HTTP 1.1 et 2
- Java 14 et les switch expressions
- Java 15 et la gestion de chaîne de caractères multiligne (enfin !), avec gestion de l’indentation s’il vous plaît ! et… le NullPointerException 😇
- Java 16 et les records
- Java 17 avec les classes scellées
- Java 18 en 2022
Bilan ? Java reste verbeux, mais se modernise et se simplifie.
Lorsque l’on parle migration sur une des LTS 11 ou 17, il faut motiver les raisons : oui c’est sympa mais ça ne suffit pas. Il faut alors parler de la JVM, qui évolue au niveau de la performance et la sécurité, notamment de nouveaux algo de crytographie. On rallie ainsi les ops. Et on peut aussi parler coût en parlant déplacement dans le cloud. On rallie ainsi la stratégie.
Il vous faut d’autres arguments ? Si vous voulez garder et attirer de nouveaux développeurs heureux : faites-les bosser sur des stacks qui ne sont pas obsolètes !
Et plus concrètement, aidez-vous de jdeps pour migrer en plus des outils et des dépendances nécessaires. Sachez qu’il n’est pas obligatoire de modulariser votre code, bien que ce soit conseillé. Donc plus d’excuses !!!
Attention cependant : depuis Java 11, il y a des API qui disparaissent ! alors oui c’est documenté, mais il faut s’y pencher pour être sûr que ça continue de compiler. Aidez-vous de javaalmanac.io par exemple.
Pour les détails de migration d’une version à une autre, je vous invite vivement à regarder la conf retransmise sur la chaîne Youtube de DevoxxFR, car Jean-Michel vous met en garde et précise les points de vigilance à avoir (notamment la gestion des warnings gniark gniark). et si vous voulez faire le grand saut de Java 8 à Java 17, le conseil est de morceler en deux étapes : d’abord passage à Java 11 avant Java 17.
Oyez oyez : Java 19 en 2023 !
et rendez-vous en 2032 pour faire le bilan !

Pour suivre Jean-Michel, ça se passe par là : @jmdoudoux
et bien sûr son site qui a fêté ses 20 ans il y a quelques mois.
Lien vers les slides
Lien vers la vidéo de Jean-Michel
Le scale-up, l’autonomie et le sous-marin nucléaire - Pauline JAMIN et Thomas PIERRAIN
C’est quoi une scale-up ? c’est une start-up qui a validé son business model et qui est en pleine extension. Dans ces cas-là : quel est le process de validation des choix ? C’est là que l’autonomie entre en jeu.

Une entreprise devrait pouvoir prendre des décisions rapidement.
Dans les faits, quand les équipes parviennent à atteindre un certain niveau d’autonomie, des limites apparaissent : faire les choses dans son coin sans en faire bénéficier les autres, se lancer dans des solutions pas forcément plus maintenable que l’existant, …
Sur la base de la référence “Turn the ship around” de David Marquet, on découvre le mode de management de la Navy, entre attentisme et suivi aveugle des ordres. Comment faire plus efficace ?
- déléguer les responsabilités
- légitimer les équipes à être force de proposition
- donner des objectifs plus que des instructions ou des procédures
- créer un espace pour échanger
Dans le contexte d’Agicap, le challenge est de passer d’une start-up à une scale-up. Mais avant d’appliquer tout cela, il faut prendre en compte certains éléments logiques et humains : la crainte du changement pour commencer.
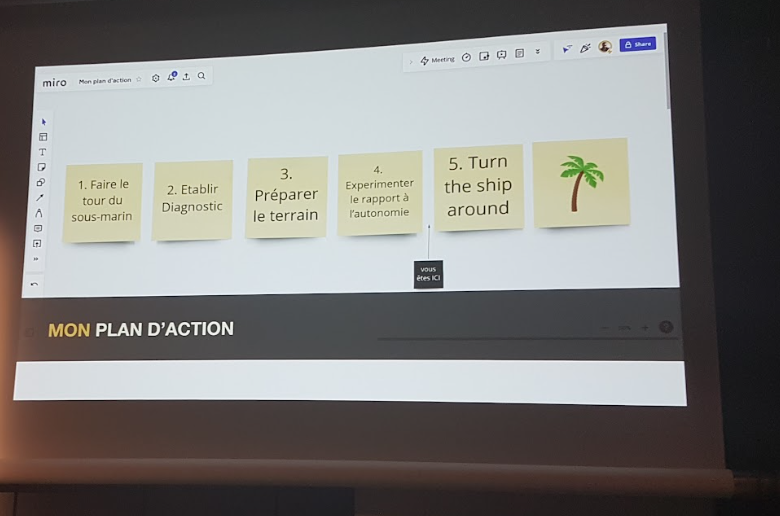
Ce qui a été testé chez Agicap : Domain Driven Sesign (DDD), la réflexion commune sur le repositionnement de chacune et chacun, la participation aux sujets de refactoring sur la base du choix, la définition d’OKR (Objectives & Key results) pour annoncer ce qui sera mesuré, mais sans préciser le comment pour laisser libre les équipes de choisir par elles-mêmes. S’ajoute aussi le lancement d’une initiative SRE.
La problématique discutée est réellement propre à la situation d’une start-up qui grossit : les applications en grosse entreprise ou chez le client ne sont pas évoquées. Cela permet néanmoins de se dire que tout est possible et de rêver un peu : merci !
Pour suivre Pauline et Thomas, ça se passe par là : @jaminpauline et @tpierrain
Lien vers les slides
Lien vers la vidéo de Pauline et Thomas
Rendez vos interfaces fiables en faisant aimer les tests à votre équipe - Jean-Lou PIERME et Jonathan MEUNIER
“tester ce que les utilisateurs ont et pas ce que notre coder fait”

Ils nous présentent leur contexte : 100% de couverture de tests (sic), méthodes testées unitairement, La notion de 100% de couverture n’est pas un gage de sécurité, ce n’est pas forcément fiable, et au final “c’est très facile d’atteindre un taux de couverture de 100%” il suffit de filouter ^^
Écrire un code “parfait” c’est chouette mais ça ne garantie pas le service qu’il fournit. L’exemple est pris d’un scénario écrit en Gherkin : cela permet de lire en langage naturel le code dans une pull request. La documentation qui peut en découler est facilement partageable.
L’avantage de ne tester que les scénarios d’usage, c’est qu’on va avoir du code non couvert de révéler, et nous aurons ainsi l’occasion de se poser la question : est-ce du code mort ? et d’intelligemment le gérer.
Pour tester, on y va par étape. A chaque bug relevé :
- on écrit un test pour qu’il passe rouge à la relance
- on corrige le bug
- on vérifie que le test passe au vert C’est du TDD appliqué à la correction d’un bug. Et on va essayé d’écrire des tests les plus petits possibles.
Lorsque l’on travaille sur du legacy, il ne faut pas tomber dans le piège de vouloir ajouter des tests sur notre nouvelle fonctionnalité et tout le reste autour. Il faut se concentrer sur notre fonctionnalité et éventuellement les branchements et les impacts avec l’existant, mais on ne va pas créer une pieuvre inmaintenable.
Un composant intéressant à utiliser pour mettre en place des tests à la base : SnapshotDiff. Puis viennent les tests unitaires, avec mock possible puisqu’on veut tester la partie technique de notre code. Ensuite, les tests d’intégration pour tester l’utilisation par l’utilisateur : on ne vérifie pas l’appel des fonctions, mais on teste le comportement, les clics, les affichages… Enfin, les tests end-to-end, sans mocks cette fois-ci pour jouer le jeu de traverser les différentes couches. La démo qui suit consiste à encapsuler toutes ces couches de tests dans du Gherkin, utilisé en JavaScript pour l’occasion.
Ce qu’il faut retenir :
- un développeur ou une développeuse doit maîtriser son environnement technique pour pouvoir écrire les tests confortablement.
- commencer par bien comprendre le besoin avant de le développer, puis d’écrire le test, refactorer, améliorer les tests
- on construit des composants légers : les tests les seront aussi
- on pense à l’asynchronisme
- on embarque correctement les nouveaux développeurs dans la démarche : “on passe autant de temps sur les tests que sur les développements”.
Pour suivre Jean-Lou et Jonathan, ça se passe par là : @jloupiote et @MonsieurNohj
Lien vers les slides
Lien vers la vidéo de Jean-Lou et Jonathan
Comment permettre 100 millions de logins sans interruption de service ? Betclic raconte son Euro 2020 de football - Nicolas JOZWIAK et Etienne PUISSANT

Il y a eu un avant et un après Euro 2020. Après avoir frôlé la faillite en 2017, Betclic a été repris par de nouveaux investisseurs exigeant le regroupement du SI (système d’informations) abandonné à Bordeaux.
L’objectif de Betclic étant d’offrir une expérience utilisateur la plus fluide possible peu importe le nombre de match possible (tout sport condonfu), la réactivité attendue de l’application est très forte. Durant toute la journée, ce ne sont pas les mêmes API qui sont sollicitées : paris, retraits, la validation des paris… c’est donc potentiellement un trafic permanent qu’il faut gérer. Appdynamics est un des deux outils qui sont utilisés pour suivre les indicateurs principaux et le monitoring front. L’autre est Datadog, qui permet de l’alerting en fonction de seuil déterminés.
Avant l’Euro 2020, s’accumulait le legacy du SI et les règles exigeantes de l’environnement des paris, notamment les notions réglementaires, propres à chaque pays de présence de Betclic (France, Pologne, Italie et Portugal). Certaines soirées faisaient tomber l’application. Sont alors nées les war-room, mettant ensemble les domaines transverses. Comprendre les bugs, prioriser les sujets : beaucoup d’améliorations sont déjà apportées en mode quick-win mais aussi plus profondément en passant d’un monolithe à du micro-services.

Les principaux points de contentieux étaient côté base de données. Un cache Redis a permis de les soulager, un cash VArnish côté front et Kong, une API gateway pour ajouter de la sécurité et de l’authentification.
Début 2020, AWS a été choisi pour passer sur le Cloud afin de passer du sentiment de “subir” les soirées de match, à l’action d’anticipation. Les premiers tests de charge ont été faits en… production !
Avec Gatling, on vient coder les différents workflow d’API pour définir des scénarios à faire ingérer à Gatling. Grâce au monitoring des simulations, toutes les équipes ont accès à l’information via un portail. Le test de charge rentre alors dans leurs habitudes et beaucoup d’améliorations niveau réseau sont apportées grâce aux tests de rupture.
Deux semaines avant l’Euro 2020, les tests de charge sont terminés. Au final, c’est 1 million de joueurs, 100 millions de login, 0 incident majeur, 0 war room. BRAVO !
“on est plutôt sereins”
Et mieux : un collectif humain s’est créé, une culture d’entreprise où chacun apporte sa contribution.
Pour la suite, il est prévu de parler auto-scaling, Azure pour le SQL Server, chaos monkey

Un grand merci messieurs, on a eu l’impression de vivre un peu l’aventure avec vous !
Pour suivre Nicolas et Etienne, ça se passe par là : @njozwiak et @TODO
Lien vers les slides - à venir
Lien vers la vidéo d’Etienne et Nicolas
CI/CD, le divorce serait-il prononcé ? - Nicolas GIRAUD et Yann SCHEPENS

A l’origine, l’intégration continue visait à améliorer le build, pour passer du code à un binaire. Avec le CD, la première étape, le delivery consiste à transformer le binaire en livrable (la partie release) mais très vite, ça devient du déploiement pour mettre l’application en production. Avec la multiplication des livraisons, on livre un service aux utilisateurs, souvent et en direct.
La CI et la CD sont donc différents mais complémentaires. Mais leur automatisation n’est pas facile et rapide tout le temps.
On parle pipeline, dans sa définition visuelle : c’est un graphe, qui sert à mettre tout le monde d’accord. Mais dans l’ensemble, pour bien le concevoir, voici des étapes clés :
- définir l’objectif du pipeline
- prendre en compte l’existant pour le faire évoluer
- y aura-t-il des étapes clés de validation ?
Un atelier d’event storming va permettre de répondre à ces trois premières questions
- définir des feedbacks pour chacune des étapes
- comment cadencer ? définir les tâches à automatiser
- choisir les outils : côté CI on est assez indépendants mais côté CD on est dépendants de l’infrastructure de l’entreprise. En choisir un seul ? plusieurs en fonction des domaines ?
Les pipelines sont évolutifs, ils suivent le même schéma d’évolution agile que le code source, pour toujours être adapté aux usages.
L’élément perturbateur est le everything as code : on met tout dans le livrable. Code, infra, doc, pipeline… ça devient vite le bazard. Le CI va avoir un impact sur la prod et la CD doit comprendre les aléas du code. La notion de DRY = don’t repeat yourself va permettre de factoriser les étapes communes… mais pas trop ! On se pose ensuite la question de savoir si les principes SOLID du dev peuvent être adaptés aux pipelines.
Il faut au maximum éviter de devoir TOUT relancer dans un pipeline pour le faire passer au vert quand une étape échoue mais toujours en observant le principe KISS (keep it simple and stupid).
Intervient la logique DevOps. Sauf qu’au lieu de simplifier la collaboration en les pratiques DEV et les pratiques OPS, on rajoute un troisième élément à part.
“Choisir c’est renoncer”
Alors, on sépare la CI et la CD ? on se répartit les responsabilités ? Ou bien se rassembler tous ensemble ?
Faisons à minima l’effort de se connaître les uns les autres, soyons empathiques, communiquons !
J’ai adoré et la forme et le fond : Nicolas et Yann sont parvenus à tenir le public éveillé à un créneau particulièrement pas facile : très belle rencontre !

Pour suivre Nicolas et Yann, ça se passe par là : @nicgiro et @YannSchepens
Lien vers les slides
Lien vers la vidéo de Nicolas et Yann
Les Cast Codeurs en 💺 et en 🦴️ - Emmanuel BERNARD, Guillaume LAFORGE, Antonio GONCALVES et Arnaud HERITIER
Tic-tac, tic-tac, il ne reste plus beaucoup de temps avant de prendre le train, les stands commencent à être démontés mais… il faut absolument que j’aille voir ces 4 sacrés personnages en vrai et en marinière ! Il y a foule, c’est bien la preuve que le partage est aussi une histoire d’affect et de personnages.

Ils sont fatigués, interrompus par les gilets rouges prêts à les suivre n’importe où, fous aussi, mais aussi assez humbles pour être reconnaissants et plein d’humour. On ne leur dira jamais assez merci, MERCI, M-E-R-C-I !! c’est incroyable ce que vous réalisez !!

Hélas tic-tac, tic-tac… il faut prendre le train. Ma consolation est d’apprendre que les dates de 2023 sont déjà fixées… rendez-vous les 12, 13 et 14 avril 2023 ❤️️
Lien vers la vidéo
C’est le bilan !
Le moins que l’on puisse dire, c’est que cette année, j’ai pu profiter un MAX !!
Donner une conférence en présence de collègues d’Apside et d’amis a été une expérience A-MA-ZING ! Avoir été accompagnée et soutenue par des gens adorables et passionnés (mention spéciale à Arnaud HERITIER, Adrien et Estelle LANDRY ainsi que les techniciens).
Les conférences et keynotes ont été ultra-variées : un grand merci à tous les speakers et au comité de sélection !
Enfin, un plus qu’énorme merci à mon amoureux Stéphane, qui m’a motivée à préparer, soumettre, qui m’a écoutée (beaucoup beaucoup…), accompagnée, coachée et qui a été tout aussi stressé que moi ❤️️
Je vous laisse avec d’autres photos souvenirs, n’hésitez pas à me les demander en ‘joli’ format si elles vous intéressent.
Les goodies de l’année dans un super sac :

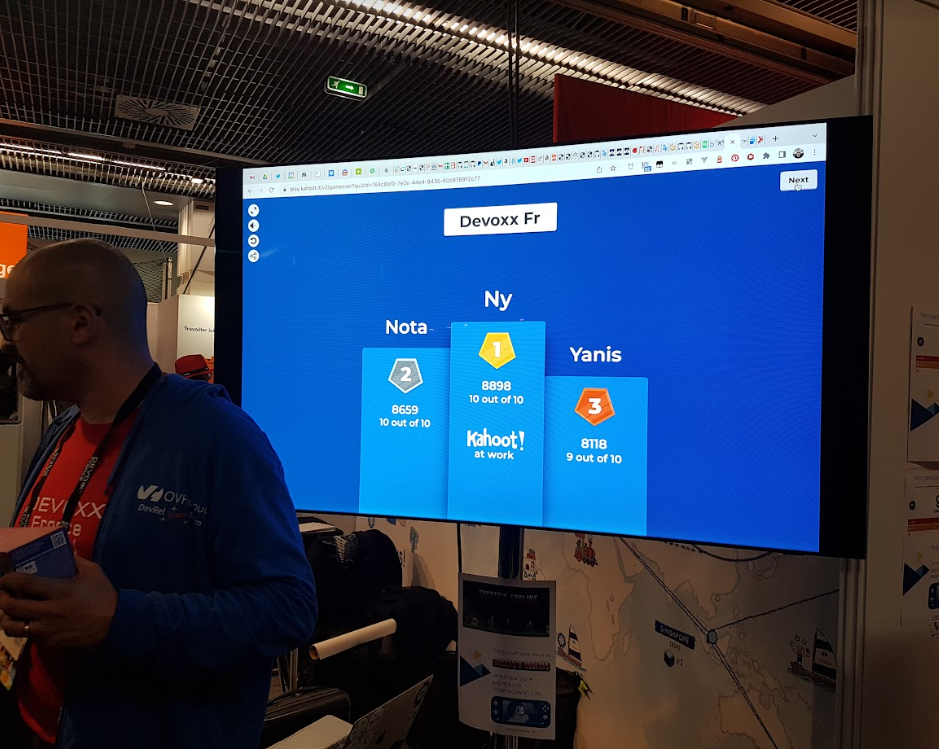
Qui qui finit 1ère du Kahoot d’OVHCloud ?
L’avant TADx :

Mon coach, Stéphane :

Aurélie juste avant le talk de Sonia :

Julien un peu avec nous malgré tout :

Arnaud et Katia présentant les keynotes :

Le dîner des speakers (je me sens toute petite) :

Gaëlle et Aurélie accompagnées par Estelle pour leur talk :

Juste merciiiiii !!!

PS : J’ai peut-être fait des fautes, écrit des bêtises => je vous invite à m’en faire part pour améliorer mon contenu !
Explore more like this

Mon DevFest Nantes 2025 à moi !
Ma dernière conférence en tant qu’attendee ? elle remonte à très très loin… Inutile de dire que j’attendais DevFest Nantes 2025 avec impatience !

Comments