Mon DevFest Nantes 2025 à moi !

Ma dernière conférence en tant qu’attendee ? elle remonte à très très loin…
Inutile de dire que j’attendais DevFest Nantes 2025 avec impatience !
Mercredi 15 octobre : préparation et voyage
“Le succès dépend de la préparation, et sans une telle préparation, il y aura certainement un échec.”
Confucius
Du coup, la question logique qui me vient immédiatement : quelqu’un a vu mes oreilles d’elfes ?
Spoiler : mon DevFest Nantes a été une grande réussite ^^
Non, en vrai, voyager la veille d’une conférence, c’est s’assurer d’être présente avant l’heure le lendemain et se garantir une place de choix dans un des plus beaux amphi que j’ai pu voir : Jules Verne à la Cité des Congrès de Nantes.
Bon, par contre, cela ne garantit pas d’éviter les retards et de découvrir une ville de Nantes by night. Au demeurant, cette première soirée a été jolie de retrouvailles (coucou Titi, MatV.Pokora, Temu et Stef !).
Pourquoi cette partie de l’hitoire est importante ?
Parce qu’en nous rendant chacun à notre hôtel, nous sommes passés devant la Cité des Congrès où s’affichait déjà fièrement la devanture du DevFest : magistrale de finesse et de beauté : des livres et grimoires posés, attendant d’être ouverts…
Je pense aux organisatrices et organisateurs, aux bénévoles, aux speakers, aux sponsors, aux participantes et participants qui ont eu la chance d’avoir des places… et me dit que je ne serai pas la seule ce soir à avoir du mal à trouver le sommeil par tant d’excitation !

Jeudi 16 octobre : premier jour féérique
Mangez bien au premier petit-déjeuner d’une conférence : vous ne savez pas quand vous allez pouvoir vous octroyer du temps pour vous ré-alimenter entre tant de sujets d’ateliers et de conférences intéressants et de discussions passionnantes…
Car même si l’organisation a tout prévu pour nous maintenir en vie et de bonne humeur, il se peut que vous soyez très vite accaparé…
ou prévoyez des Pom’potes ;-)
Chapitre 1 : Il était une fois DevFest Nantes 2025
L’amphi Jules Verne se remplit, les bénévoles et les orgas sont déjà aux petits soins pour nous placer le mieux possible.
C’est un Jef-Dracula et une Annabelle-Poppy qui ouvrent ce premier chapitre de présentation d’avant Keynote.
La scène est majestueuse, les costumes sont incroyables (bravo Ptibulle !) et j’ai beaucoup de mal à retranscrire en live l’émotion d’être présente (je me relirai posément par la suite et rajouterai ceci : je suis toujours dans l’émotion de cette ouverture deux jours après ^^).

Chapitre 2 : Keynote - Advice Well Taken - Dasha Ilina
Dasha est une artiste qui questionne notre obsession de la technologie au travers de ses différents projets :
- Surveillance dans les villes
- étude des douleurs physiques ressenties par rapport à nos usages du numérique
- observation du temps passé sur nos outils (surtout pendant la période COVID)
- observation des outils dans le domaine social
- question autour du stockage d’énergie dans notre recherche permanente du tout électrifié
Alors qu’elle zoome sur le projet “conseil bien suivi” aka “Advice Well Taken”, Dasha nous montre deux ressources qui l’ont inspirée dans son projet artistique :
- un site web qui recense et document différentes histoires et contes
- un autre site web, plus ancien, dont la dernière parution date de 1971, “The Last Whole Earth Catalog” dont le but était de partager des informations sur les modes de vie alternatifs et les outils associés, et que Dasha analyse comme un précurseur de nos usages de nos réseaux aujourd’hui.
A partir de ces observations, elle a l’idée de nommer le folklore autour de la Tech : le “Techklore”.

Alors y a-t-il un équivalent aujourd’hui ?
OUI dans la façon dont nous partageons les informations sur nos différents réseaux sociaux.
De ces usages, toujours plus importants, surgit la question de la limite entre paranoïa et risques réels encourus : sommes nous surveillés ? espionnés ? utilisés ?
Dasha parcourt un certain nombre de cas qui nous font sourire, mais réfléchir aussi :
- utilisation du cache-caméra, d’un bout de scotch sur l’entrée du micro de nos ordinateurs
- nos commportements de contournement, comme l’utilisation de nos téléphones sous la douche pour écouter la musique (à l’époque hein ! maintenant il y a des enceintes bluetooth pour cela les gens !!)
- nos convictions partagées mais pas toujours rationnelles (mettre son téléphone dans du riz cru lorsqu’on a renversé du liquide dessus, réparer les micro-fissures de son écran de téléphone avec du dentifrice…)
Force est de constater qu’on ne comprend pas toujours comment fonctionne nos produits (téléphone, application, connexions…) mais on les utilise massivement, en confiant ces tâches à des Big Techs qui conservent leurs façons de faire secrètes.
Si je résume : moins on en sait, plus on fait confiance ?
La force de l’effet boîte noire.
Même si on est réfractaire au début d’une nouvelle façon de faire, quand le groupe valide un usage, on est rassuré et on passe le pas.
Alors au final, a-t-on le pouvoir sur nos outils ?
pas sûre…
Pour suivre Dasha sur les réseaux, ça se passe sur Instagram : dashesandcommas
Lien vers les slides - à venir
Lien vers la vidéo de Dasha - à venir
Chapitre 3 : La légende des Lecteurs d’Ecran : une odyssée sensorielle au coeur de nos apps - Océane Gillard et Patrice de Saint Steban
Il y a plusieurs façon de participer en tant qu’attendee à une conférence. la première consiste à assister, écouter, s’enrichir, noter en étant assis dans un siège puis poser des questions éventuellement aux speakers en fin de présentation. Cela demande déjà de sortir de sa zone personnelle de sécurité (se mêler à la foule, oser poser une question…).
La seconde demande un effort supplémentaire (mais tellement enrichissante !) : aller en atelier, prendre en main une problématique, essayer de la résoudre… au risque d’échouer ? non, au risque d’apprendre encore plus !
Ni une ni deux, c’est l’occasion pour moi de surmonter mon illégitimité à pratiquer (depuis que je ne code plus qu’en side projects), et découvre les possibilités d’amélioration d’accessibilité des sites par la pratique.
petite émotion supplémentaire : l’atelier se passe en salle Machines, qui se trouve être la salle où j’ai donné mon atelier avec Stéphane Philippart il y a deux ans et qui est un de mes meilleurs souvenirs d’atelier…
Océane et Patrice ont eu l’idée de cet atelier à la suite d’un projet de refonte du site de la MAIF.
Si, on le sait, des règlementations existent depuis 2005 via une loi obligeant les services numériques publics à être accessibles, il a fallu des amendes pour “convaincre” les entreprise de sauter le pas.
Après avoir parlé de WCAG avec les différents niveaux d’accessibilité AAA et la transposition française RGAA, nous passons en mode atelier :
- installer l’outil d’accessibilité android ✅
- vérification des différents moyens de parcourir un site sur téléphone et… on se lance ! Paramètres > Accessibilité > TalkBack > Utiliser
Attention : je suis sous Androïd (un magnifique Samsung des années 2010), les manipulations seront différentes si on est sous iOs.
On commence par comprendre la navigation de base :
- un clic > description de ce que c’est (texte, bouton, …)
- 2 clics > activation
On déroule ainsi le mode opératoire disponible via Talkback pour apprendre à revenir sur l’écran d’accueil, à aller sur une application récemment ouverte, à monter et baisser le son du TalkBack, à revenir sur la page précédente… et l’ouverture du menu TalkBack en appuyant sur l’écran avec trois doigts (ne serait-ce que pour l’arrêter pour le reste de la journée, sous peine de s’entendre décrire les notifications reçues à tout bout de champs ^^).
ça parait facile hein ?
ma galère à moi : bien voir… bon mais ça biaise tout l’exercice -> merci aux speakers de nous avoir fournis des bandeaux !!!

Première quête : on se noue les bandeaux sur les yeux et on essaie d’utiliser la calculatrice. Déjà, il faut la trouver dans nos menus. Léger biais : je sais exactement où trouver l’application en favoris sur la deuxième page de mon écran d’accueil.
Une fois lancée et malgré le peu de boutons possibles, on subit déjà la recherche sur l’écran tactile sans repère. Heureusement, le fonctionnement “à deux étapes” permet de tâtonner gentiment : on clique sur le 4 (enfin on essaie) et tant qu’on ne le trouve pas, on ne double-clic pas pour l’activer.
Biais supplémentaire : je connais très bien mon clavier de calculatrice, qu’en serait-il d’un clavier inconnu ?
Deuxième quête : touver la distance entre DevFest Nantes et Zenika Nantes -> ce n’est pas “juste” chercher Zenika…
Je triche un peu au départ et choisis mon application google Maps après moults péripéties à ne pas trouver l’application les yeux fermés…
puis… la découverte : on ne peut pas tâtonner, comme pour la calculatrice, l’ensemble du clavier alpha-numérique de la barre de recherche et double-cliquer que lorsqu’on valide le carctère choisi. Il va falloir balayer le clavier jusqu’à ce que la lettre entendue vous convienne.
On s’y fait assez vite (même si mes gros doigts n’aiment pas le “a”, je ne sais pas pourquoi).
Là aussi autre biais : je sais que mon clavier est azerty et j’ai l’habitude de taper au clavier, donc je sais à peu près où aller chercher mes lettres.
Mais ça ne s’arrête pas là : il faut trouver l’info précise de la distance : les yeux ouverts et bien voyants, c’est facile de cliquer au bon endroit, mais les yeux fermés, c’est une autre paire de manche.
Il faut balayer avec un doigt vers la droite pour passer d’information en information, et écouter patiemment si on obtient l’information tant recherchée…
au total : 21 balayages pour savoir que je suis à 1,5km de Zenika Nantes ! Cela interroge aussi sur la logique de lecture d’un écran et/ou le nombre d’informations sur une page.
Troisième et dernière quête sur téléphone (je n’ai pas réussi sur le moment dans le temps imparti mais j’y suis revenue par la suite) : aller sur le site de DevFest Nantes et trouver le nombre de participants…
Moralité de l’histoire : nos téléphones ne sont pas organisés de manière accessibles, on ne sait pas par coeur où chercher.
En réalité, les personnes qui ont l’habitude d’utiliser TalkBack “écoutent vite” là où nous avons tâtonné.
Autre retour intéressant d’une personne mal voyante : l’aspect spatiale du clavier “impalpable” du téléphone est déroutant vis-à-vis d’un clavier de PC où on peut se sentir plus à l’aise avec les touches sans les voir.
C’est aussi un avantage des applications mobiles versus les pages webs : les informations sont réduites au minimum ce qui limite un peu la navigation et permet d’aller vite à l’info recherchée.
Et l’IA dans tout ça ?
En tant qu’utilisateur, se servir de l’IA pour balayer un site, c’est bien et ce n’est pas bien : c’est bien quand la conception du site sur lequel on est n’est pas waouh. L’IA permet alors de potentiellement l’améliorer. Mais elle risque de rentrer en concurrence de certaines notions voir faire des contre-sens.

On passe maintenant à l’analyse et la correction d’un site au niveau accessibilité : balises html <div> utilisées à tort et à travers, contrastes pas optimisés… On analyse le code et on teste la navigation via TalkBack sur nos téléphones.
On apprend rapidement et efficacement de nos “erreurs”, j’aime beaucoup cette façon d’itérer. Et en plus l’atelier est pensé de telle façon que quoiqu’il arrive, nous aurons la correction a posteriori.
Les premiers tips que je me suis notés :
- utiliser des balises
<alt>pour décrire les images, les vidéos… même pour votre SEO c’est utile ! A la rigueur, si on ne veut pas forcément la retranscrire parce que l’image n’est pas importante (d’abord, pourquoi l’ajouter alors ? ) mais à la rigueur indiquer un<alt>vide. - l’information ne doit pas être portée uniquement par la couleur : elle doit être doublonnée par du texte, une icône détaillée… quelque chose qui permette de faire le focus dessus.
- donner les informations importantes en premier, c’est-à-dire faire le focus sur les usages prioritaire : j’ai bein aimé l’exemple très parlant, sur nos boîtes mail, lorsque nous souhaitons écrire un mail, nous ne voudrions pas balayer TOUS les mails de notre messagerie avant de pouvoir cliquer sur le petit + (non au scroll infini ^^)
- repenser la lecture “naturelle” pour qu’elle devienne plus “logique” avec le tabindex=0
- Aria-live : pour avertir d’une nouveauté, soit en mode polite (attend ce qui est en train de se lire avant de prendre la parole) ou assertive (il coupe la parole parce que c’est vraiment important, genre pour une erreur).
- typer les titres / boutons pour s’adapter au mode de lecture voulu par l’utilisateur (qui peut effectivement choisir de lire d’abord les titres)
Alors quid des framework incluant de l’accessibilité ? il faut faire le même travail d’analyse ! ce n’est pas parce que le framework apporte ses composants accessibles, qu’ils sont de base bien utilisés : à vos loupes, Sherlock Holmes en herbe !
J’ai beaucoup écrit sur cette partie, mais l’atelier m’a vraiment branchée.
Alors si je dois résumer : ayez la structure html la plus logique possible, quitte à refaire du CSS par la suite !
Un grand merci Océane et Patrice pour cet atelier et votre disponibilité 🙏
Pour suivre Océane et Patrice, ça se passe sur LinkedIn : oceane-gillard et patrice-de-saint-steban
Lien vers les slide
Chapitre 4 : Charmer les dragons : pitcher son produit comme un héros - Montaine Marteau et Rachel Dubois
13h28 je suis dans la salle Les Machines.
Comment ça l’atelier ne commence qu’à 14h ?
Oui mais je VEUX ma place (et elles sont chères quand on sait que c’est 2300 personnes par jour qui vont venir à DevFest Nantes cette année…).
Pourquoi cette impatience ?
Parce que Rachel, parce que Montaine et parce qu’en terme de transmission d’infos et d’apprentissage, on ne peut mieux tomber. S’assurer une place à ce workshop, c’est gagner 8 points de progression et d’ouverture d’esprit sur une échelle de 10.
Et puis par curiosité aussi autour du sujet qui n’est clairement pas mon expertise.

L’atelier est tellement prenant que ces quelques notes sont écrites a posteriori.
Plantage du décor : on doit toutes et tous faire face à un dragon un jour : il est là, pas forcément gigantesque, mais dressé entre nous et notre objectif. La seule façon de l’affronter est de le combattre ? Non : nous allons apprendre à l’embarquer, le convaincre de nous suivre, mais comment ?
Pas d’incantations manipulatrices sombres et obscures mais des techniques bien huilées (et préparées !) pour soi-même faire le tri entre envie personnelle et réel intérêt pour les autres.
Il a d’abord fallu penser à une expérience concrète et personnelle où l’on a eu besoin de pitcher un besoin, un service ou un produit.
Acte I : de l’importance de résoudre une problématique.
Si on veut que notre idée aboutisse, il faut avoir de l’impact, il faut que ça compte. L’idée est donc de passer tour à tour par 4 points simples :
- scène 1 : décrire un problème clair et réel : faire ressentir le problème que nous allons résoudre
- scène 2 : utiliser le story telling pour apporter une solution élégante à cette problématique
- scène 3 : chiffrer ! prouver ! démontrer que la solution est LA solution car les chiffres marquent les esprits
- scène 4 : conclure que la vision du projet, le but.
Par feedback interposé, nous nous sommes posé les questions en binôme (merci à Loïc d’avoir permis de le faire dans d’excellentes conditions !) pour définir si ce premier pitch nous avait donné envie d’écouter, si nous avions compris et le problème et la solution, si la posture, le ton, la preuve paressaient crédibles et si nous nous étions sentis inspirés, prêts à accepter.
Acte II : pimper ce même pitch, avec des techniques avancées.
Grâce à quelques extraits vidéos inspirantes, nous avons parcourus différentes autres techniques, telles que :
- le héros, le dragon et le trésor (storytelling)
- l’arc narraftif express
- la règles des 3 raisons, 3 problèmes, 3 chiffres, 3 bénéfices…
- le mode Disney (le fait d’utiliser les contrastes pour accentuer, pas le fait de faire disparaître les mamans dès les premières secondes du pitch !!)
- le silence stratégique
- le rythme crescendo
- etc…
Bilan : notre deuxième version a été incroyablement plus percutante, plus crédible et plus embarquante.
Pourquoi j’ai adoré l’approche utilisée et cet atelier en général : parce que ça parle et ça doit servir à tout le monde. Orienter un choix techniques, prendre part à une décision d’équipe, demander une reconnaissance, innover, négocier du temps pour innover (celles et ceux qui me connaissent bien me voient venir…), bref : c’était une session de partage utile et sans frontière.
Un ENORME merci à Rachel et Montaine qui nous ont embarqués dans leur monde féérique pour mieux ré-atterrir dans le nôtre.
Pour suivre Montaine et Rachel, ça se passe sur LinkedIn : montaine-marteau et duboisrachel
Lien vers les slides - à venir - et ils sont trop beaux 🤩
Chapitre 5 : Terramate l’outil qui fait scaler votre code Terraform - Mathieu Herbert
Je change encore de sujet.
Terrraform aujourd’hui ne permet pas de générer simplement des environnements multiples. Or pour celles et ceux qui mettent en production au quotidien (bien sûr que c’est possible ! même le vendredi !), on aimerait bien que ce soit le même code qui soit identique en dev comme en prod.
En outre, se rajoute le besoin de traçabilité (DevOps oblige) et de monitoring (a minima les détections de changements.
Pour répondre à ces besoins, Mathieu nous introduit l’outil Terramate, entreprise EU qui propose un outil Terramate Cloud, une UI, pour gérer des workflows et être alerté. Il vient avec un autre outil open source CLI pour générer du code et orchestrer des déploiements de stack.
Let’s go pour la démo !
Terramate se base sur de la génération de code, avec une partie plus flexible sur la syntaxe (pour les boucles par exemple !).
Mathieu nous a montré très efficacement les stacks exemples (instanciation du code généré), des variables avec valeur par défaut, qu’on pourra surcharger pour chaque stack (y compris localement !), le mode opératoire pour créer une nouvelle stack avec changement de valeur des variables, puis un init sur les stacks existantes qui montre la différence de comportement entre une stack existante non modifiée d’une autre nouvellement créée par exemple et enfin la possibilité d’importer du code Terraform vers Terramate grâce aux tags.
Chez Dataiku où travaille Mathieu, ils utilisent Terraform pour gérer de l’AWS, de l’Azure, de l’Iam, des Github action… C’est avec Terramate qu’ils assurent la traçabilité et la validation ET du code ET de la stack.
Concernant la partie détection : ils ont mis en place Drift detection.
Terramate se lance toutes les nuits (pas forcément sur toutes les stacks, il est possible d’en exclure, toujours sur la base de tags) et s’il y a détection de changement, un envoi de message vers Slack est programmé avec une notification au commiter qui, dans leur process, se doit de résoudre l’alerte pour qu’elle ne ré-apparaisse pas au check de la nuit suivante.
Mon avis : je suis carrément convaincue que Terramate peut être un outil facile à installer et à utiliser. Mais comme l’a précisé Mathieu, la partie CI/CD se doit d’être travaillée en amont. Je vois donc cette étape comme une deuxième marche intéressante à monter une fois une CI minimale posée.
Pour suivre Mathieu, ça se passe par sur LinkedIn : mathieu-herbert-347b0b7a
Lien vers les slides - à venir
Lien vers la vidéo de Mathieu - à venir
Chapitre 6 : OSINT : L’art de trouver ce qui ne devrait pas être trouvé - Marie Viley
Dernière conférence de cette première journée.
Marie nous présente les techniques d’OSINT (open source intelligence). Bien que je découvre le nom, les principes ne nous sont pas étrangers : nous avons toutes et tous plus ou moins eu recours à ce genre de méthode.
Quelles méthodes ?
Celles qui permettent de collecter, centraliser et rendre accessibles des informations sur les réseaux, articles de journaux…
Ainsi on recoupe les informations de plusieurs sources à partir de détails connus : c’est par exemple le principe utilisé pour construire son arbre généalogique.
OSINT c’est aussi une branche de la cyber sécurité car bien évidemment, certaines utilisations sont malveillantes. Marie nous a ainsi raconté le cas de Strava, application bien connue des grands sportifs (ou de celles et ceux qui comme moi, connaissent des grands sportifs ^^). L’application a permis de retrouver le déplacement de certaines personnes à partir de leur photo. Jusque là, pas trop de mal, sauf que cela a été fait pour retrouver des personnes stratégiques et élaborer des plans malveillants.
Plusieurs spécialités d’OSINT dans la syber ont été évoquées : SOCMINT, IMINT, SIGINT, FININT, GEOINT, CTI / CYBINT.
Beaucoup d’outils cités aussi (il faudra revoir la vidéo car ils n’étaient mentionnés qu’à l’oral).
Ainsi OSINT est énormément utilisé pour le domaine judiciaire, ou des organismes d’investigation, voire des volontaires (comme vous et moi) pour faire avancer des affaires ou pour de mauvaises actions par des personnes malveillantes (pas comme vous et moi).
Si vous êtes intéressés pour réaliser des défis OSINT, Marie nous a partagé des infos précieuses :
- OSINT 4FUN
- OSINT FR
- REDDIT r/OSINT
- CTF
- et pour les collégiens et lycéens : Plateforme TOP (pour faire notamment attention à ses données sur les réseaux sociaux)

Pour suivre Marie, ça se passe sur LinkedIn : marieviley
Lien vers la vidéo de Marie - à venir
Chapitre 7 : Bilan de la première journée
Quelle journée ! Croiser d’anciennes connaissances, nouer de nouveaux liens, s’enrichir de l’avis des autres… les émotions et les savoirs se mêlent, les conférences sont des expériences uniques où le plus difficiles est de “profiter un maximum”.
De mon programme initialement écrit, je n’ai loupé qu’une seule conférence, que je verrai avec toutes les autres quand elles seront publiées par le GDG Nantes. Hâte…
Lien vers la playlist complète des vidéos - à venir
Vendredi 17 octobre : deuxième jour incroyable !
Réveil matinal pour la bonne cause : le programme de cette deuxième journée est encore une fois complet !
Chapitre 8 : Karpenter * Keda : le duo gagnant du FinOps - Guillaume Membré et Sébastien Fourreau
Guillaume a encore grandi (si si c’est possible !) et il forme le duo gagnant de ce démarrage de journée avec Sébastien.
Suite à leur dernière migration de Cloud Provider (vers AWS), ils nous proposent un retour d’expérience sur comment optimiser le nombre de pods et de VM sur un cluster Kubernetes.
Au départ, il faut savoir que tout ce qui est sur Amazon est facturé :
- facturation à l’heure que l’on ait 0 ou 1000 noeuds pour faire tourner les applicatifs (sur quantité de CPU, RAM…)
- plus compliqué : la pile réseau (load balancer qui distribue le traffic) -> facturation dessus dès qu’ils sont UP et selon la quantité de données qui transitent = 25 euros par mois + traffic
- traffic inter AZ = datacenter distribués sur la région et dès que plusieurs pods se parlent -> tarification aussi 1 centimes par gigas, ça monte très vite
- Control plane environ 73 euros par mois Ainsi, globalement, le coût total est difficlement prévisible.
Alors quelques questions se posent : mieux vaut faire plein de petits noeuds ou peu de gros noeuds ? il n’y a pas forcément de bonne réponse.
Doit-on faire du sur-provisionning ? oui au cas où… mais ça coûte très vite très cher.
Doit-on privilégier le on-prem (pet) ou le Cloud (cattle) ?
Le parti pris : avec des VM sur approche type cloud, on ne garde pas en vie une VM qui ne se porte pas bien -> on jette et on remonte. C’est donc là qu’on peut optimiser.
Keda permet justement dans ce cadre de faire de l’auto-scalling, basé sur des scalers de type :
- built-in (prépackagé avec la solution Keda) Prometheus, RapbbitMQ, elastic search
- external (Keda ayant une interface gRPC) : plus difficile à maintenir
On peut trouver 4 briques dans Keda :
- Keda operator : il regarde les évènements et change le nombre de pods par rapport aux infos founies par…
- …Metrics Server
- Scalers lui se connete à une source d’évènement
- CRDs : custom ressource definition pour étendre l’api Kube avec des ressources custom
L’architectue de Keda est adaptée à une utilisation variante tout au long de la jounée, en gérant des paramètres de scheduling précis. La facturaiton liée peut alors être en mode spot et/ou on-demande, selon ce que l’on a paramétré. Attention simplement à ce que les applications soient sans état pour ne pas avoir trop de difficultés à gérer les disques (même si dans le faits c’est possible).
Voici l’architecture simplifiée :
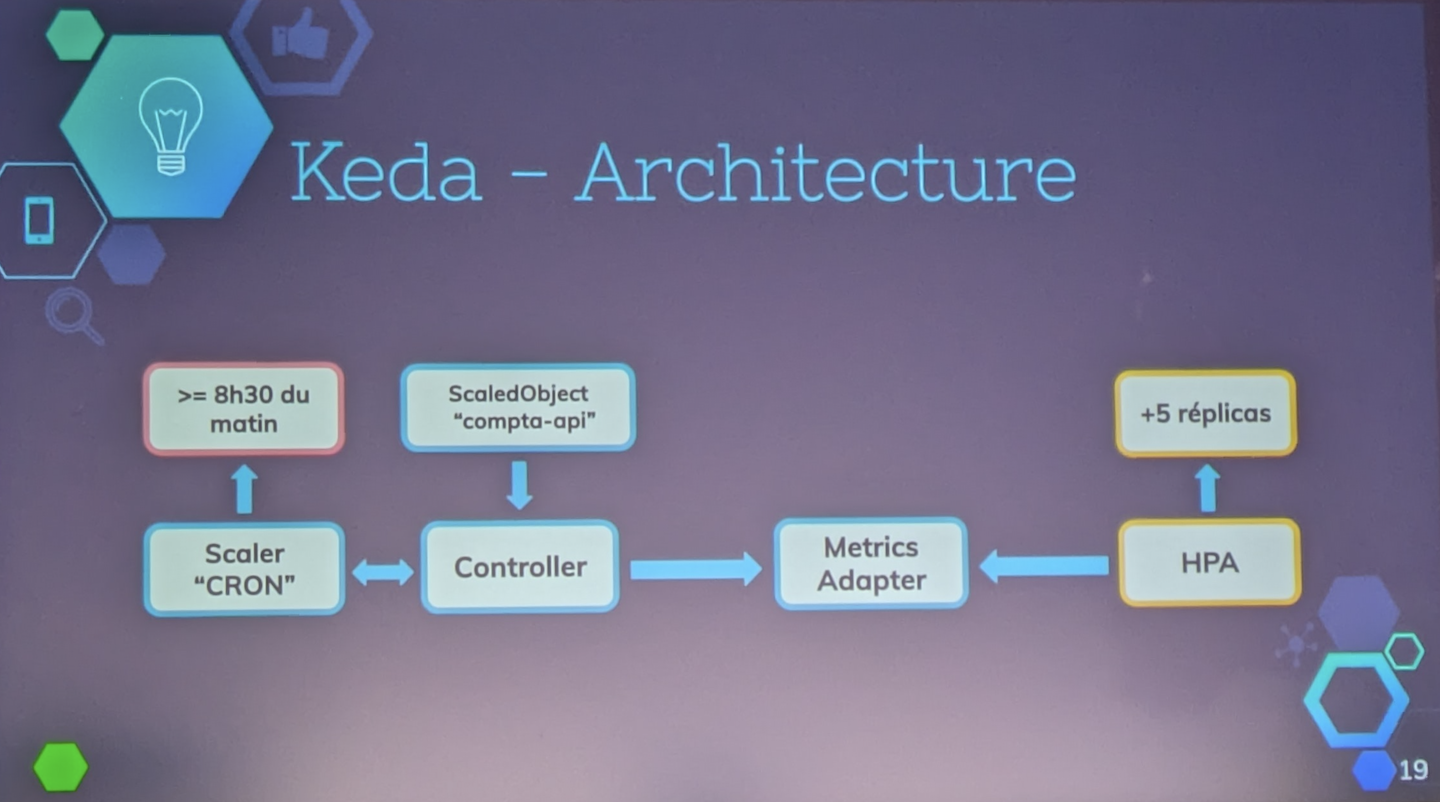
- Controller = cerveau qui fait le lien avec tous les composants
- ScaledObject qui définit le besoin en termes de réplica
- Metrics sur lesquelles se base …
- … Scaler pour que…
- … Metrics Adapter s’adapte et envoie au …
- …HPA (horizontal pod autoscaler)
- et Workload adapte
Une optimisation consiste à tout mettre au même endroit, de maximiser la centralisation. On précise alors les ressources minimales dont on a besoin en mode cattle et le scheduler se débrouille, et le scale up est accéléré par Karpenter qui va déterminer les pods full ou disponibles.
Je découvre ensuit le principe de consolidation (dans ma jeunesse je disais aussi défragmentation 😇 ).
Cette optimisation permet de réduire les coûts en distribuant les charges (et donc il FAUT des replicas des appli !).
Avec Nodepool, on peut indiquer le nombre de CPU max à utiliser et limiter le nombre de nodes par tranche horaire par exemple (scale up uniquement possible mais pas de destruction de VM entre 11h et 16h par exemple) -> vraiment à adapter à notre contexte particulier.
Modifier la durée de vie des VM est aussi possible -> ainsi la version d’OS est toujours OK, sans mise à jour à gérer (et ça, en effet, ça me parle bien 😅 ).
Donc en résumé :
- Keda fait varier le nombre de pods
- Karpenter fait varier le nombre de noeuds
Et pour les différents modes de facturation (on-demand, usage traditionnel…), on peut là aussi adapter le mode en fonction de la temporalité. Cela a permis à Guillaume et Sébastien par exemple, de se permettre un temps d’observation assez long (1 an) pour faire varier les modalités de facturation et les optimiser (j’adore ce principe d’empirisme, mais j’ai du mal à croire qu’on me laissera un temps d’observation aussi long sans optimisation 🥲 ).
Je découvre le mode spot : pour rentabiliser les machines qui sont peu uilisées la nuit ou le weekend -> on peut baisser le prix, mais attention, il y a une contre-partie : les VM peuent être réclamées dans les 3 minutes. C’est donc à Karpenter de démarrer sur une autre AZ ou sur autre mode de facturation (donc encore une fois, c’est adapté pour les applications sans état ou des batchs plus ou moins longs qui peuvent reprendre là où ils se sont arrêtés sans problème).
Il y a ensuite d’autres options (mais là il faut que je creuse car c’est allé trop vite pour moi) : reserved / instance / savind plans : engagement sur 1 à 3 ans, pour les bases de données par exemple (?).
Enfin, une autre optimisation possible : changer defamille de noeuds, par exemple passer de m5a à m6a a fait réaliser à Guillaume et Sébastien 25% d’économies.
A la fin de leur retour d’expérience, le duo entrevoit déjà d’autres optimisations possibles : affiner le nombre de pods en heures creuse, scaling dynamique au cours de la journée, passage en instance Graviton (processeur ARM) avec un gain estimé de 10%…
En espérant qu’ils reviennent un jour refaire un REX mis à jour ^^
Pour suivre Guillaume et Sébastien, ça se passe sur LinkedIn : gmembre et Sébastien - à venir
Lien vers les slides
Lien vers la vidéo de Guillaume et Sébastien - à venir
Chapitre 9 : Révolutionnez votre prise de notes : du Bullet Journal à Obsidian - Hoani Cross
C’est la toute première conférence pour Hoani, et il a assuré.
Passionné de dessins et de caligraphie, il a souhaité allier cette passion à la prise de notes.
Prendre des notes, pour lui, c’est ancrer en mémoire, en ralentissant (on pose son téléphone !) et en zoomant sur ce qu’on retient d’essentiel. On le synthétise et on le retranscrit parfois avec nos propres mots. Et c’est ainsi que nous alimentons notre mémoire à long terme.
On connecte nos idées, on construit notre bibliothèque, on créé des interconnexions.
Clairement le sujet fait plus que me parler : j’ai découvert Obsidian il y a 2 ans, j’ai commencé à l’utiliser de manière professionnelle, jusqu’à ce qu’il m’ouvre des perspectives personnelles assez velues :
- ce que je suis : ma cartographie pro et perso
- ce que j’aime : mes lectures, mes concerts, mes conférences, mes jeux passés ou à venir
- ce que j’aime moins mais que j’aimerai renforcer : des cours, des tutos, …
Mais aussi ce que ça peut apporter aux autres, lors de mes sessions de coaching individuel ou d’équipe.
Une des caractéristiques communes à beaucoup de recherches d’opportunités ou de rassurance ? Bien se connaître. En tant que personne ou en tant qu’équipe. C’est donc assez naturellement vers Obsidian que nos explorations naissent (encore plus adéquat d’ailleurs quand les séances se font à distance).
Alors comme Hoani, j’ai un goût assez prononcé (et terriblement ancré) pour le papier : les calepins (tout types de calepins !), les stylos (tous types de stylos !!) et autres gadgets qui ne servent pas à grand chose mais qui en deviennent nécessaire (ah le nombre de post-it transparents et de marque-page personnalisés que je peux cumuler…).
Mais il faut se rendre à l’évidence : un calepin, ce n’est pas scalable. Et j’ai beau adorer coller et plier mes origamis pour que ça tienne quand même dans un cahier… la relecture n’en est pas toujours facilitée.
Hoani nous présente donc son Obsidian personnel comme étant un mix entre prises de notes et un bullet journal, vous savez, la structuration de votre journée remplie de ce que vous devez faire, ce que vous faites réellement, vos émotions ressenties, vos “compteurs” du jour (en fonction de vos besoins : nombres de pas, nombres de parties jouées, nombre de calories, nombre de courriers traités…).
Hoani gère ainsi son quotidien et les périodes de l’année comme une revue, une rétrospective et une planification. Si le contenu m’a quelque peu effrayé (par empathie, ma charge mentale est passée de “il faut que je pense / arrive à lui dire un truc, akai” avant la conférence à “oulala mais ça me serait impossible de faire des sprint planning et des revues de sprint de ma journée, semaine, mois… de ma vie personnelle !!” en fin de conférence).
Je me suis donc plutôt intéressée à la forme et à la technique possible dans Obsidian pour, un jour, rapporter tout cela comme levier à une équipe ou une personne que j’accompagne.
Il existe bien évidemment des alternatives numériques à Obsidian : Onenote, Evernote, Notion… tout dépend d’avec quoi on est à l’aise et je pense que la maîtrise de chaque outil demande de toute façon du travail.
Avantages du numérique d’abord :
- la navigation entre les pages, avec références multiples possibles, pas seulement “le sens de la lecture du format papier”
- le copier-coller : et oui quand même ! ce n’est pas négligeable
- l’automatisation d’actions
Avantages d’Obsidian :
- nous restons propriétaires de nos données
- format markdown donc accessible rapidement pour celles et ceux qui sont habitués (.md)
- multi-plateforme
- écosystème de plugins Open Source
On peut voir Obsidian comme un coffre de fichiers de formats divers (notes, audio, images, diapositives) et qui permet de bénéficier d’une vue graphique assez élégantes (en tout cas moi, l’effet wahou fonctionne à chaque fois).
Tips supplémentaires :
- on peut s’inventer des conventions d’écriture : c’est assez chouette de pouvoir personnaliser ses prises de notes, et je trouve que ça en fait la force de l’outil Obsidian. C’est comme avoir toute une palette de tampons et couleurs sans avoir à les porter ^^
- la synchronisation des fichiers qui sont intialement en local (pour quelque 4$ de plus…)
- stockage cloud si souhaité
- plugin git disponible (attention cependant : conseillé que pour de l’archivage car considéré comme plugin instable sur mobile), mais à creuser pour l’utilisation en mode équipe
- autres plugins : Periodic Notes, Tasks, Dataview, Templater
- emoji disponibles pour les métadonnées (spécial clin d’oeil à Aurélie Vache, Gaëlle Accas, Philippe Charrière et Stéphane Philippart !)
- les tâches sont requêtables comme des les tableaux dynamiques
- il est possible de créer des variables réutilisables dans tout le template
Je sors de cette conférence en ayant tout plein d’idées de choses à tester : merci Hoani !

Pour suivre Hoani, ça se passe sur LinkedIn : hoanicross
Lien vers les slides - à venir
Lien vers la vidéo de Hoani - à venir
Chapitre 10 : Rencontre sur les stands
Contexte particulier du jour : ce n’est pas un stand Apside mais un stand CGI qui nous réprésente cette année à DevFest Nantes 2025.
J’en profite donc pour faire connaissance, notamment avec l’elfe-sauveuse Anne-Claire CHIARENZA et Cédric LE BRETON : m’est avis que nous allons écrire une belle histoire commune tout bientôt. C’est aussi ça la magie des contes 😇
J’en profite aussi pour faire un coucou sur le stand de Proginov que j’ai justement rencontré au DevFest Nantes 2023 et avec qui j’ai beaucoup aimé travailler.
Chapitre 11 : Agents intelligents, la nouvelle frontière des LLMs - Guillaume Laforge
Comment ça je suis sensée l’avoir déjà vue cette conférence là ?
Oui… c’est vrai que Guillaume est passé à TADx - Tours agile & DevOps experience - au mois de septembre dernier. Mais sachez que pour que ce super meetup tourangeau se déroule dans les meilleures conditions je loupe systématiquement les 15 premières minutes (commande de pizza oblige…).
Alors là, séance de rattrapage, dans la plus belle salle de la cité des congrès !
Et la salle est bien bien remplie.
LLMs, RAG, agent IA… faisons un petit tour d’horizon des bonnes pratiques et des framworks qui peuvent vraiment nous aider, sur base de démos en… Java ! J’en connais qui sont très contents…
LangChain4j et ADK (Agen Development Kit) : Guillaume est commiter sur les deux frameworks, les explications qui vont suivre seront d’autant plus intéressantes.
Rapidement, qu’est-ce qu’un AI agent ?
La formule est “simple” : AI Agent = LLM + memory + planning + tool use.
memory ? car oui, on va avoir besoin de renvoyer régulière la totalité du contexte agrémenté des réponses précédentes
planning ? comment font les LLM pour découper les tâches complexes en sous-tâches ou sous LLM
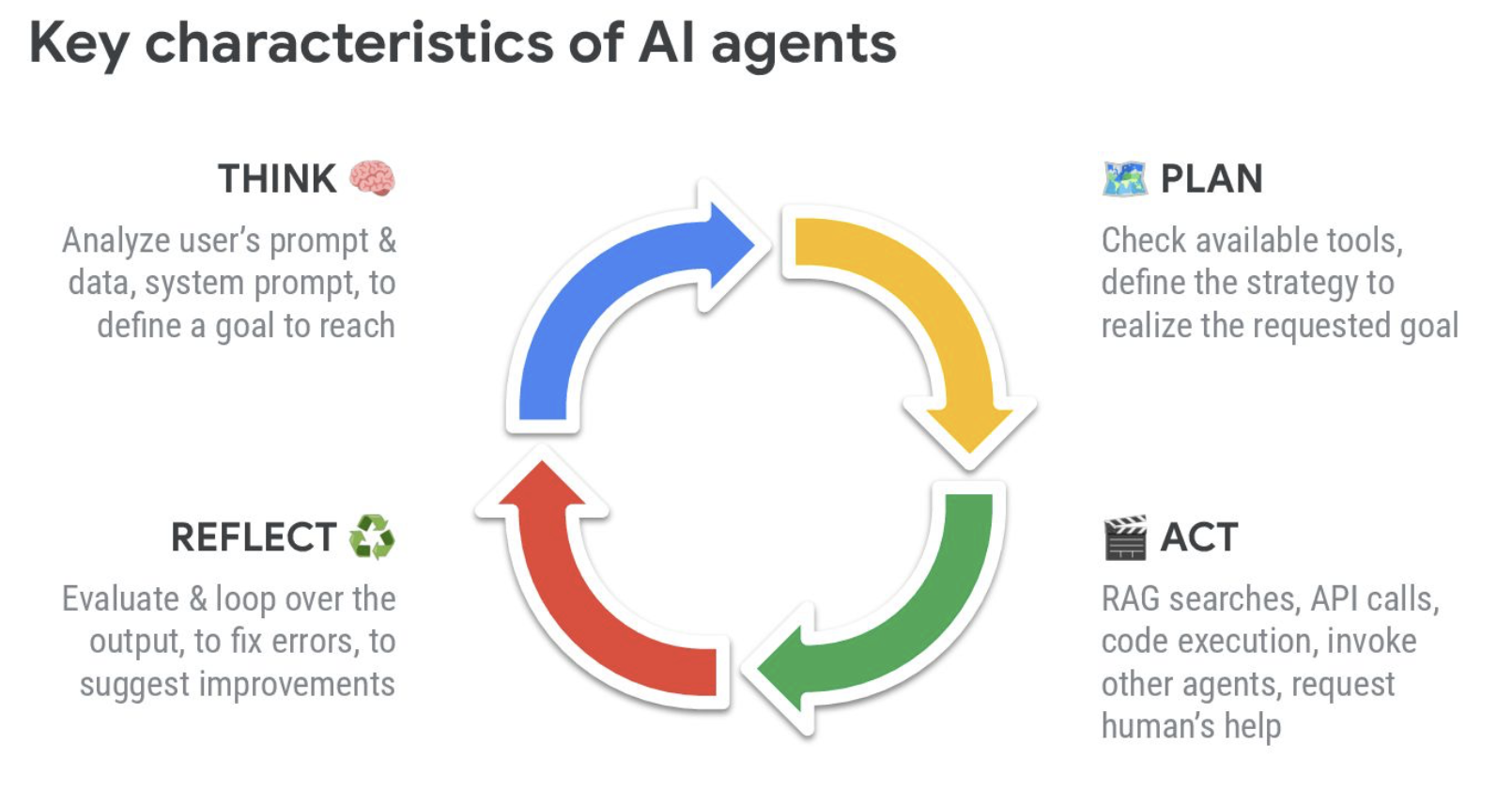
Les grandes caractéristiques des agents me fait penser à la roue PDCA que l’on utilise dans le concept d’amélioration continue : plan - do - check - act. Notamment sur la partie “reflect” qui permet de relancer la boucle si l’analyse faite présente des manques par exemple sur le contexte. Je vais réfléchir à cette analogie où finalement, humain comme agent, rendent l’erreur positive en la conscientisant et en l’analysant pour en faire une version améliorée…
D’ailleurs, au niveau du planning, ça peut être l’agent, l’utilisateur ou un programme / workflow qui décide.
On s’intéresse au function calling : c’est ce qui est à la base des agents pour interagir avec son environnement.
Le LLM n’appelle jamais de fonction directement. C’est le framework qui va envoyer le prompt au modèle (Gemini dans le cas de la démo) mais aussi une fonction qui existe et qui va orienter la réponse.
Le modèle répond à l’application le renvoi de l’appel à la fonction et c’est donc le framework qui appelle réellement la fonction donc appel à l’API, qui reçoit la réponse de l’API et renvoie la réponse à donner au LLM qui la retransmet enfin à l’utilisateur… Comment ça je ne suis pas claire ? OK… voici l’illustration :
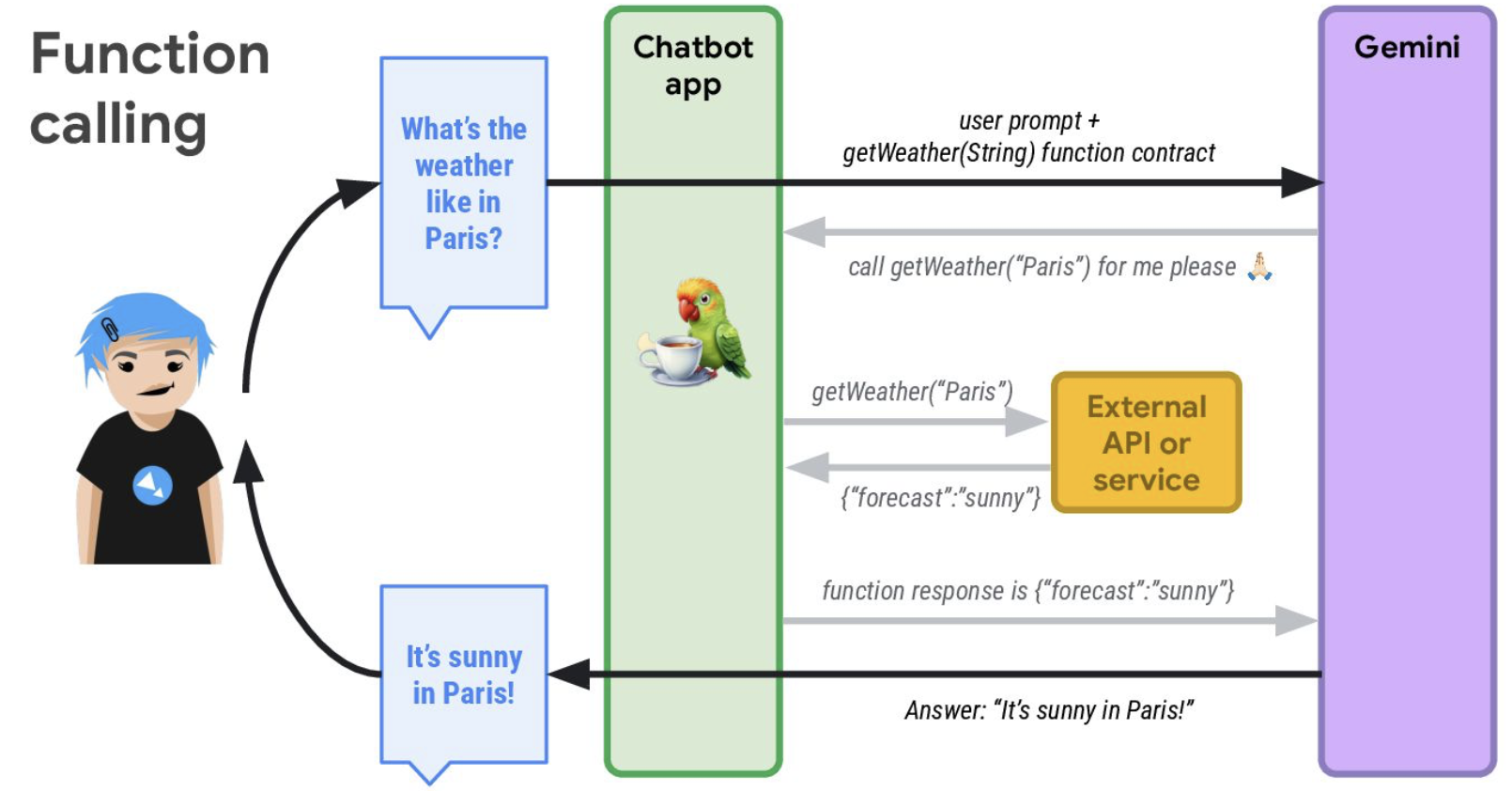
Les flux de control peuvent être séquentiels / parallèles / avec condition de routage / par boucle.
Et quid des décisions cruciales à prendre ? Principe HITL - Human in the loop : pour vérifier les réponses !!!
Enfin Guillaume nous parle de la partie reflection & self critique (ReAct pattern) : le modèle observe le contexte pour savoir si ce qui a été généré est correct ou pas. C’est la fameuse prise de recul citée plus haut.
Et c’est parti pour les trois démos !
1- Scène 1 : le RAG
Le RAG est un pattern pour être capable de chercher dans ses propres données, docs…
Attention : le RAG est entrainé jusqu’à une certaine date -> il y a donc une notion de “vérité jusqu’à telle date”.
La première phase d’ingestion consiste à centraliser les documents de tout format, de les découper en petits morceaux, d’utiliser un embedding model qui va calculer des vectoriels (représentation sémantique multidimensionnelle) -> et les bouts de textes similaires vont avoir des vecteurs qui vont pointer vers le même endroit.
Ainsi le vecteur d’une question dans le prompt est assez proche du vecteur de la réponse, ce qui permet dans la deuxième phase de retrieval, de trouver des vecteurs et extraits de texte qui sont les plus proches de la question. On le met dans le prompt du LLM qui va se baser dessus pour synthétiser la réponse.
La complexité de la question déterminera le nombre d’étapes nécessaires (j’adore l’exemple que prend Guillaume : “quel est le nom du président du pays dans lequel on trouve la tour eiffel dans la capitale ?” -> on va bien avoir plusieurs questions en une).
Pour y réponde, on utilise un Agentic RAG qui lui, découpe les questions en plusieurs topics, et le topic assistant va être appelé x fois (une fois par topic) avant de renvoyer les réponses à l’assistant agentique qui sera capable de résumer le tout.
2- Scène 2 : Authoring Agent
Tous les jours, un site web est amendé d’une histoire générée avec des images et du texte, avec à chaque fois 5 chapitres (avec ImaGen de Google).
Tous les jours à minuit, un cron Google Cloud Scheduler appelle l’application qui va driver le workflow, choisir un type d’histoire (space opera, scifi…) : 5 prompts pour générer les 5 chapitres. Ensuite il appelle le générateur d’image avec ces prompts -> ce sont, à chaque appel, 4 images par défaut qui sont générées, se rajoute donc une étape de sélection de celle qui correspond le mieux au chapitre.
3- Scène 3 - Création du pont entre LangChain4j et ADK développé par Guillaume.
L’idée de ADK c’est de faire différents niveaux d’agents.
Une DevUI vient avec ADK et on peut voir les détails de l’appel, on peut cliquer pour avoir des détails et voir aussi l’aspect graphique des étapes.
Ce que je retiens de la conférence de Guillaume : les agents sont non déterministes ! 🤣
On en a eu la preuve par l’effet démo, superbement maîtrisée par Guillaume, merci pour cette conférence efficace 🙏

Pour suivre Guillaume, ça se passe sur LinkedIn : glaforge
Lien vers les slides de Guillaume
Lien vers la vidéo de Guillaume - à venir
Chapitre 12 : Quand le Terminal dévore la UI : TUI pour tout le monde ! - Thierry Chantier
Fan de panda, de métal et de terminaux, Thierry nous présente le principe TUI.
Une application TUI “prend toute la place” et permet l’interface homme-machine.
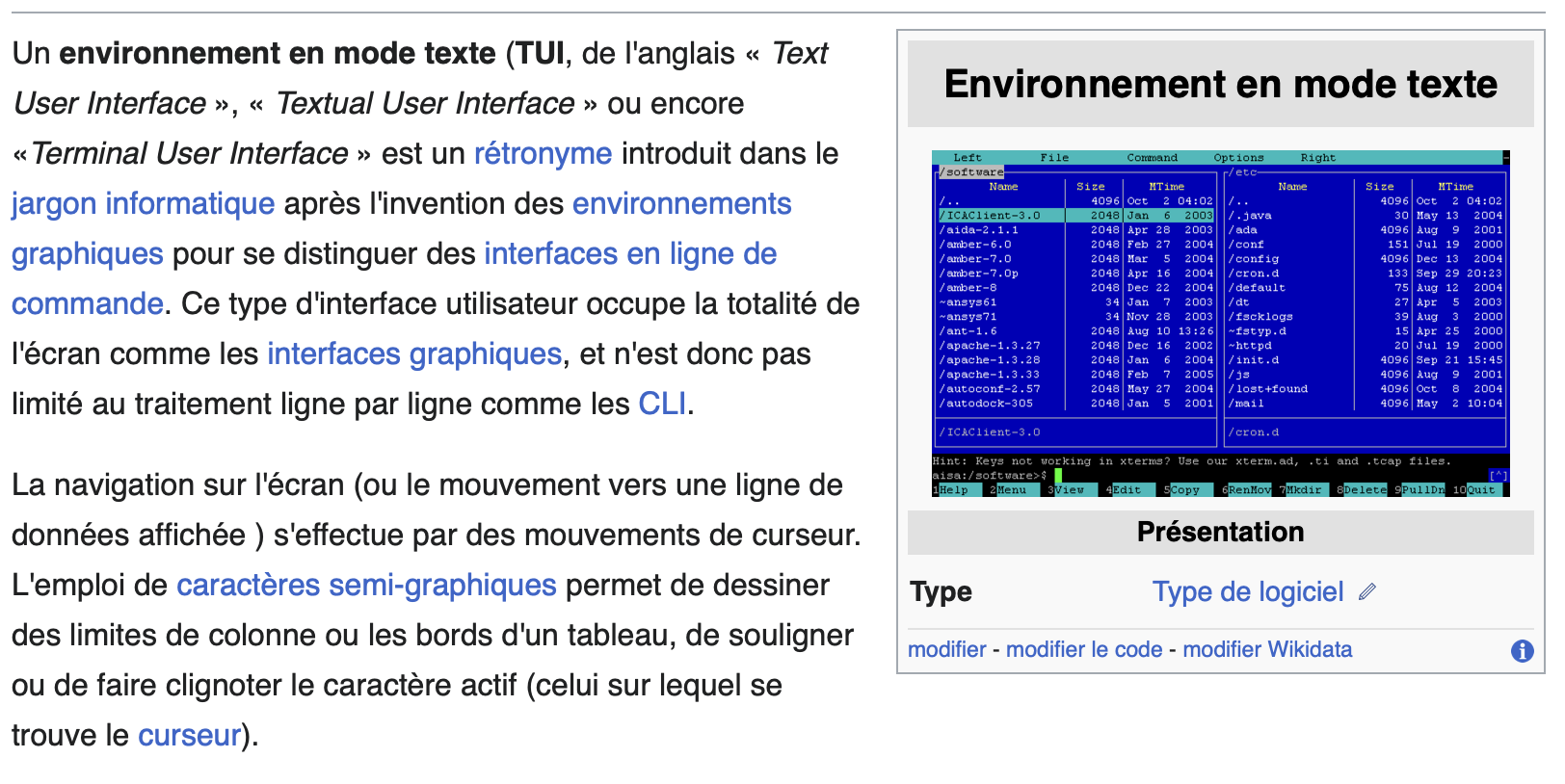
En mode histoire, on parcours carte perforées, télégraphes, mécanographie, télescripteur, VT100, ATARI, Windows, Ubuntu, MacOS… Le public est, je pense, composé de beaucoup de fans qui sont heureux de cette rétrospective revival.
On découvre aussi l’outil posting, genre de postman où on navigue par tabulation ou souris.
Parti pris de Thierry : pour que la TUI corresponde à son besoin, il faut la développer soit même.
Mais comment ? on parle de picocli, mais c’est une CLI, c’est encore autre chose…
Il y a bien Lanterna mais ce n’est pas idéal.
Il y a le projet de Jake Wharton mais c’est un peu lourd et un peu trop side project.
Du côté de chez Spring, il y a springUI (merci Stéphane !).
Allez go : Scène 1 : Thierry nous embarque dans une première démonstration à base de Spring Boot (on n’oublie pas les “;” hein…)
Classe Hello Nantes, composant helloLesGens, et bonne pratique : partir d’une box View !
Menu dans le header et helpers de raccourci clavier dans le footer : on retrouve nos petits au fur et à mesure.
Scène 2 : et en Python ?
librairie typer, rich, textual (avec mêmes types d’infos qu’en CSS).
fonction compose, onglets.
Scène 3 : en Go.
se renseigner sur charms, bubbletea et cobra pour la partie TUI
Scène 4 : en Rust (mon voisin de droite vit sa meilleure vie)
Et pour cause : c’est peut-être le framework le plus puissant pour faire des TUI (clap)
& le framework ratatui.
J’ai bien aimé l’idée intéressante évoquée : l’accessibilité dans les TUI. ça tombe bien : il peut exister des thèmes prédéfinis dans un json récupérable.
Bientôt une Scène 5 ? Thierry nous a parlé de COBOL en partant… vraiment ?
To be continued…

Pour suivre Thierry, ça se passe sur Bluesky : @TitiMoby
Lien vers les slides de Thierry
Lien vers la vidéo de Thierry - à venir
Chapitre 13 : JBang, un fichier Java pour les gouverner tous ? - Stéphane Philippart
Alors on ne va pas se mentir, le sujet, je le connais, le présentateur, je le connais, et en fin de dernière journée c’était exactement ce qu’il me fallait : un sujet à re-découvrir, adapté en mode contes et légendes.
Pour s’affranchir de la lourdeur du squelette apporté par du classique Maven lors de la création d’un projet, JBang nous permet de faire des scripts aussi simplement qu’en Python ou en bash.
Alors pourquoi pas faire du Python ou du bash Stéphane ?
Ah oui… parce que tout ce qui peut être fait en Java, doit être fait en Java 😆
De manière bien huilée et bien rythmée, on découvre en 20 minutes les premiers avantages possibles à utiliser JBang.
Petit kiff de conférence : j’adore l’utilisation des snippets pour à la fois gagner du temps en démo sans se planter sur un caractère et passer 10 minutes à corriger, tout en permettant au publlic de lire le contenu.
Et big-up aussi à Ambre PERSON, MC (maître de cérémonie) de Stéphane pour l’occasion.
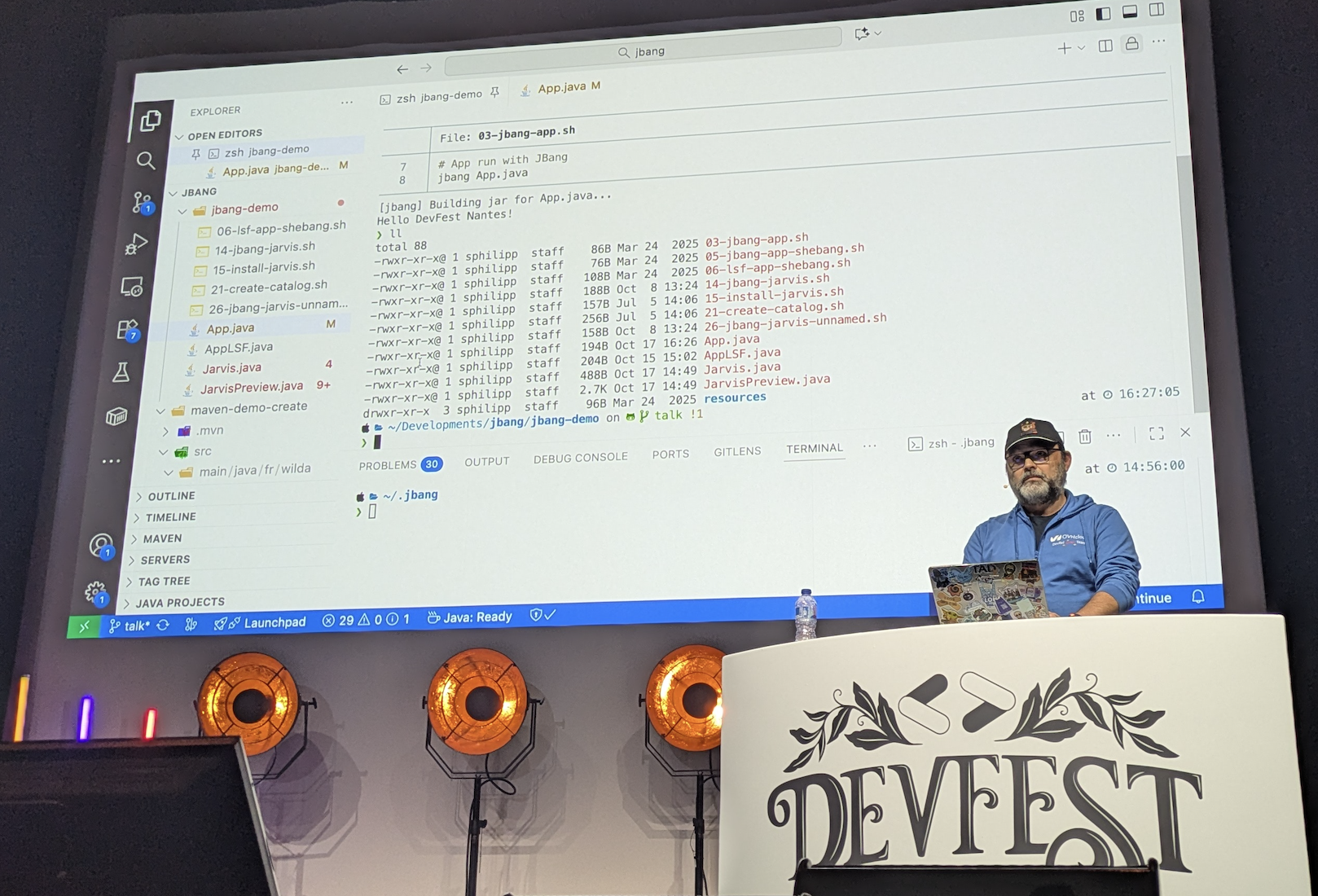
Pour suivre Stéphane, ça se passe sur Bluesky : @wilda
Lien vers les slides de Stéphane
Lien vers la vidéo de Stéphane - à venir
Chapitre 14 : Embellir des QR Codes à l’ère de la GenAI - Raphaël Semeteys
Les QR Codes (Quick Response Codes), à l’origine, ça vient du Japon : inspiré du jeu de Go, ils permettenr de stocker du contenu numérique, du binaire ou des Kanji.
Avec un mécnisme de correction d’erreur, ils restent lisibles et interprétables même si le QR Code est endommagé.
Il est composé de :
- 3 marqueurs de position
- un pattern d’alignement pour gérer l’orientation
carré noir vaut 1
carré blanc vaut 0
Alors comment gére-t-on les erreurs ? en ajoutant des données (cf. implémentation de Reed-Solomon).
Donc, il est tout à fait possible d’ajouter une image dedans : c’est un hack de la gestion d’erreurs (à condition que ça reste entre 7 et 30% max de l’image).
Pour cela, Raphaël nous a parlé de son uilisation de deux outils :
- Stable Diffusion, qui fait du débruitage progressive d’une image, guidé par un prompt et une image
- ComfyUI, pour la génération d’image, qui fonctionne en local
Il nous a ensuite montré la technique de ControlNets (composants supplémentaires équivalent à des modèles d’IA), et plus spécifiquement de QR Code Monster, et aussi d’Image Prompt Adapter et de l’animation possible avec Advanced Live Portrait.
Sur la base de ses démos pré-enregistrées, nous avons pu suivre “en live” l’exécution du tout pour petit à petit, donner un “thème” à nos QR Codes, puis une image générée et enfin… une image animée ! et cela sans dénaturer la lecture du QR Code en question…
Très esthétique, visuel et beau pour finir cette deuxième journée : merci Raphaël !

Pour suivre Raphaël, ça se passe sur LinkedIn : raphaelsemeteys
Lien vers les slides - à venir
Lien vers la vidéo de Raphaël - à venir
Chapitre 15 : Keynote de clôture : mais quelle sera-t-elle cette fois-ci ?!
Et bien, après avoir eu la chance, il y a deux ans, de monter sur scène pour une session Burger Quizz façon Pop-Corn sur le thème du cinéma, ce soir c’est une troupe de théâtre d’improvisation qui nous fait rire à l’unisson : métier de Cloud Architect revu et corrigé façon moyennageuse en Architecte de nuages, exercices de répartition de la parole et d’inventions de situations les plus cocasses… C’était la meilleure façon de clôturer cette édition.
Un grand merci à la troupe la Faltazi !
pardon pour la qualité de la photo : elle est floue, je riais trop…

Bilan de cette édition DevFest Nantes 2025
Le moins que l’on puisse dire, c’est que cette année, j’ai pu profiter un MAX !!
Un grand merci à mon manager Simon MOITIE pour cette occasion en or : je reviens avec plein d’idées à partager.
Un ENORME merci à toute l’équipe d’organisation et de bénévoles : Jef, Annabelle, Julien, Lise et toute l’équipe.
Bravo aux MC qui ont lancé les sessions de conférences de si belle / drôle / fantastique manière.
Bravo pour tout ce que vous avez mis en place pour que tout le monde se sente en environnement sûr : speakers, sponsors, participantes et participants.
Depuis Devoxx France 2025, j’avais fait une pause dans les conférences, ça m’a fait un bien fou de discuter avec vous toutes et tous.
Mention spéciale à Marjorie pour sa gentillesse légendaire, Sonia pour son humanité sincère, Rachel et Montaine pour ce duo formidable de bonne humeur et de rires, Thomas et Mathieu (ou l’inverse) pour respectivement leur Pom’ptes, le Jagerbomb et les olives (les oreilles d’elfe vous vont si bien), Natalia pour son sourire rayonnant, Thierry pour ses passions folles et ses expérimentations, Marie et notre fou rire (on ne dira pas pourquoi), Julien pour sa générosité débordante, Denis et Quentin pour leur duo sympatique, Guillaume pour sa simplicité touchante, Laurent pour ses pommes, Raphaël pour sa bienveillance et bien sûr mon inégalable et irremplaçable moitié Stéphane.
Merci aussi à toutes celles et ceux avec qui j’ai pu discuter, apprendre ou rigoler, je reviens boostée grâce à vous : Olivier H., Jérôme, Ambre, Pierre, Nicolas G., Benjamin, Olivier L., Antoine, Jean-Phi, Jimmy et l’équipe Devoxx présente : Nicolas M., Zouheir, Quentin, Marie, Estelle, Fred, Elysia…
Merci, merci, merci.
PS : J’ai peut-être fait des fautes, écrit des bêtises => je vous invite à m’en faire part pour améliorer mon contenu, par PR ou par mail.
Explore more like this

Mixit 2022 - des crêpes et du coeur
Mixit est une conférence à Lyon accessible à tous. Elle propose des thèmes très variés autour de la tech. Y participer, c’est soit avoir la chance d’être sélectionné en tant...

Comments